
很有可能,您使用了一种更流行的工具,例如 Ahrefs 或 Semrush 来分析您网站的反向链接。
这些工具在网络上搜索,以获取链接到您网站的网站列表,其中包含域评级和描述反向链接质量的其他数据。
反向链接在 Google 的算法中发挥着重要作用已经不是什么秘密了,因此在将其与竞争对手进行比较之前,至少了解您自己的网站是有意义的。
虽然使用工具可以让您深入了解特定指标,但学习自己分析反向链接可以让您更灵活地了解您正在测量的内容以及它的呈现方式。
尽管您可以在电子表格上进行大部分分析,但 Python 具有一定的优势。
除了可以处理的行数之外,它还可以更容易地查看统计方面,例如分布。
在本专栏中,您将找到有关如何使用 Python 考虑不同链接属性来可视化基本反向链接分析和自定义报告的分步说明。
不占座
我们将从英国家具行业中挑选一个小型网站作为示例,并使用 Python 进行一些基本分析。
那么网站的反向链接对于 SEO 的价值是什么?
最简单的,我会说质量和数量。
质量对于专家来说是主观的,但通过权威和内容相关性等指标对谷歌来说是确定的。
在评估数量之前,我们将首先使用可用数据评估链接质量。
是时候编码了。
导入重新
导入时间
导入随机
导入熊猫作为pd
导入numpy作为np
导入日期
时间从日期时间导入timedelta
从plotnine导入*
导入matplotlib.pyplot作为plt
从pandas.api.types导入is_string_dtype
从pandas.api.types导入is_numeric_dtype
导入uritools
pd。 set_option(‘display.max_colwidth’, None)
%matplotlib 内联
root_domain = ‘johnsankey.co.uk’
hostdomain = ‘www.johnsankey.co.uk’
主机名 = ‘johnsankey’
full_domain = ‘https://www.johnsankey.co.uk’
target_name = ‘John Sankey’
我们首先导入数据并清理列名,以使其更易于处理并更快地为后期阶段键入。
target_ahrefs_raw = pd.read_csv(
‘data/johnsankey.co.uk-refdomains-subdomains__2022-03-18_15-15-47.csv’)
列表推导式是清理列名的一种强大且不那么密集的方法。
target_ahrefs_raw.columns = [col.lower() for col in target_ahrefs_raw.columns]
列表理解指示 Python 将数据框列中每一列 (‘col’) 的列名转换为小写。
target_ahrefs_raw.columns = [col.replace(”,’_’) for col in target_ahrefs_raw.columns]
target_ahrefs_raw.columns = [col.replace(‘.’,’_’) for col in target_ahrefs_raw.columns]
target_ahrefs_raw.columns = [col.replace(‘__’,’_’) for col in target_ahrefs_raw.columns]
target_ahrefs_raw.columns = [col.replace(‘(‘,”) for col in target_ahrefs_raw.columns]
target_ahrefs_raw.columns = [col .replace(‘)’,”) for col in target_ahrefs_raw.columns]
target_ahrefs_raw.columns = [col.replace(‘%’,”) for col in target_ahrefs_raw.columns]
虽然不是绝对必要的,但我喜欢将计数列作为聚合的标准,如果我需要对整个表进行分组,我喜欢使用单值列“项目”。
target_ahrefs_raw[‘rd_count’] = 1
target_ahrefs_raw[‘project’] = target_name
target_ahrefs_raw
Pandas 截图,2022 年 3 月
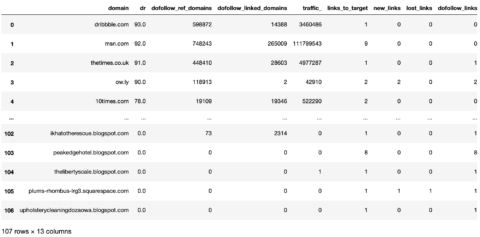
现在我们有一个具有干净列名的数据框。
下一步是清理实际表值并使它们对分析更有用。
复制先前的数据框并为其命名。
target_ahrefs_clean_dtypes = target_ahrefs_raw
清理 dofollow_ref_domains 列,它告诉我们站点链接有多少个 ref 域。
在这种情况下,我们会将破折号转换为零,然后将整列转换为整数。
#refering_domains target_ahrefs_clean_dtypes[‘dofollow_ref_domains’ ]
= np.where(target_ahrefs_clean_dtypes[‘dofollow_ref_domains’] == ‘-‘,
0, target_ahrefs_clean_dtypes[‘dofollow_ref_domains’])
诠释)
#linked_domains target_ahrefs_clean_dtypes[‘dofollow_linked_domains’ ]
= np.where(target_ahrefs_clean_dtypes[‘dofollow_linked_domains’] == ‘-‘,
0, target_ahrefs_clean_dtypes[‘dofollow_linked_domains’])
诠释)
First_seen 告诉我们第一次找到链接的日期。
我们会将字符串转换为 Python 可以处理的日期格式,然后稍后使用它来推导链接的年龄。
# first_seen
target_ahrefs_clean_dtypes[‘first_seen’] = pd.to_datetime(target_ahrefs_clean_dtypes[‘first_seen’], format=’%d/%m/%Y %H:%M’)
将 first_seen 转换为日期还意味着我们可以按月和年执行时间聚合。
这很有用,因为并非总是每天都会获取网站的链接,尽管如果这样做对我自己的网站会很好!
target_ahrefs_clean_dtypes[‘month_year’] = target_ahrefs_clean_dtypes[‘first_seen’].dt.to_period(‘M’)
链接年龄的计算方法是将今天的日期减去 first_seen 日期。
然后将其转换为数字格式并除以一个巨大的数字得到天数。
# 链接年龄
target_ahrefs_clean_dtypes[‘link_age’] = datetime.datetime.now() – target_ahrefs_clean_dtypes[‘first_seen’]
target_ahrefs_clean_dtypes[‘link_age’] = target_ahrefs_clean_dtypes[‘link_age’]
target_ahrefs_clean_dtypes[‘link_age’] = target_ahrefs_clean_dtypes[‘link_age’] .astype(int)
target_ahrefs_clean_dtypes[‘link_age’] = (target_ahrefs_clean_dtypes[‘link_age’]/(3600 * 24 * 1000000000)).round(0)
target_ahrefs_clean_dtypes
Pandas 截图,2022 年 3 月
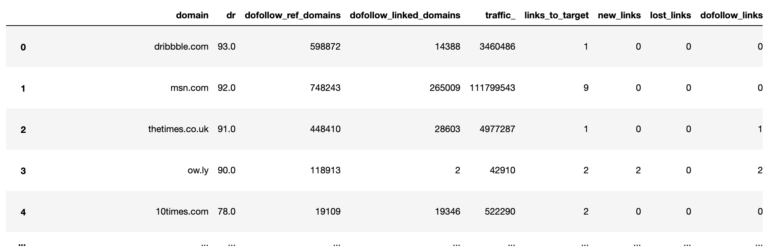
清理完数据类型并创建了一些新的数据功能后,乐趣就开始了!
链接质量
我们分析的第一部分评估链接质量,它使用 describe 函数汇总整个数据帧以获得所有列的描述性统计信息。
target_ahrefs_analysis = target_ahrefs_clean_dtypes
target_ahrefs_analysis.describe()
Pandas 截图,2022 年 3 月
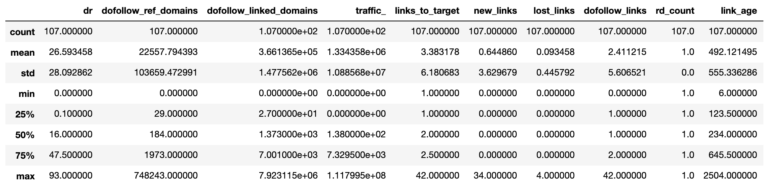
所以从上表中,我们可以看到平均值(mean)、引用域的数量(107)和变化(第 25 个百分位等)。
引用域的平均域评级(相当于 Moz 的域权限)为 27。
那是件好事儿吗?
在这个市场领域没有竞争对手数据可比较的情况下,很难知道。这就是您作为 SEO 从业者的经验所在。
但是,我敢肯定,我们都同意它可能会更高。
换档要高多少是另一个问题。
 Pandas 截图,2022 年 3 月
Pandas 截图,2022 年 3 月
上表可能有点枯燥且难以可视化,因此我们将绘制一个直方图来直观地了解引用域的权限。
dr_dist_plt = (
ggplot(target_ahrefs_analysis, aes(x = ‘dr’)) +
geom_histogram(alpha = 0.6, fill = ‘blue’, bins = 100) +
scale_y_continuous() +
theme(legend_position = ‘right’))
dr_dist_plt
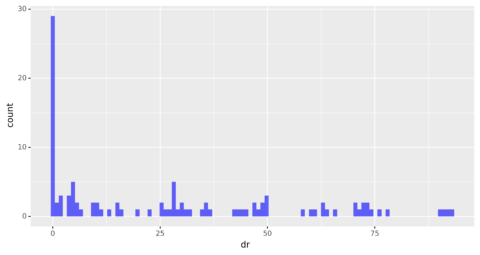 截图来自作者,2022 年 3 月
截图来自作者,2022 年 3 月
分布严重偏斜,表明大多数引用域的权威评级为零。
超过零时,分布看起来相当均匀,不同权限级别的域数量相同。
链接年龄是 SEO 的另一个重要因素。
让我们看看下面的分布。
connection_dist_plt = (
ggplot(target_ahrefs_analysis,
aes(x = ‘link_age’)) +
geom_histogram(alpha = 0.6, fill = ‘blue’, bins = 100) +
scale_y_continuous() +
theme(legend_position = ‘right’))
links_dist_plt
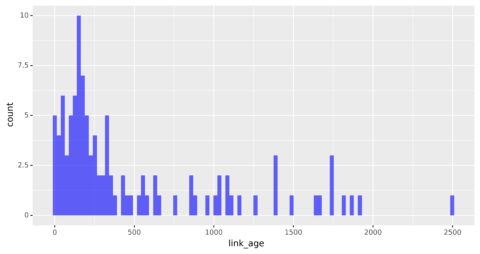 截图来自作者,2022 年 3 月
截图来自作者,2022 年 3 月
分布看起来更正常,即使它仍然偏斜,大多数链接都是新的。
最常见的链接年龄似乎是 200 天左右,不到一年,这表明大多数链接是最近获得的。
出于兴趣,让我们看看这与域权限有何关联。
dr_linkage_plt = (
ggplot(target_ahrefs_analysis,
aes(x = ‘dr’, y = ‘link_age’)) +
geom_point(alpha = 0.4, color = ‘blue’, size = 2) +
geom_smooth(method = ‘lm’, se =错误,颜色 = ‘红色’,大小 = 3,alpha = 0.4)
)
print(target_ahrefs_analysis[‘dr’].corr(target_ahrefs_analysis[‘link_age’]))
dr_linkage_plt
0.1941101232345909
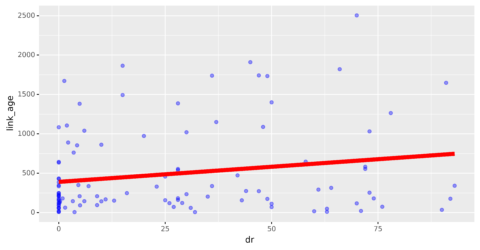 作者截图,2022年3月
作者截图,2022年3月
该图(连同上面打印的 0.19 数字)显示两者之间没有相关性。
为什么应该有?
相关性仅意味着在站点历史的早期阶段获得了更高权限的链接。
不相关的原因将在稍后变得更加明显。
我们现在将查看整个时间的链接质量。
如果我们要按日期逐字绘制链接数量,时间序列看起来会相当混乱且不太有用,如下所示(没有提供代码来呈现图表)。
为此,我们将按一年中的月份计算域评级的运行平均值。
注意 expand( ) 函数,它指示 Pandas 将所有先前的行包含在每个新行中。
target_rd_cummean_df = target_ahrefs_analysis
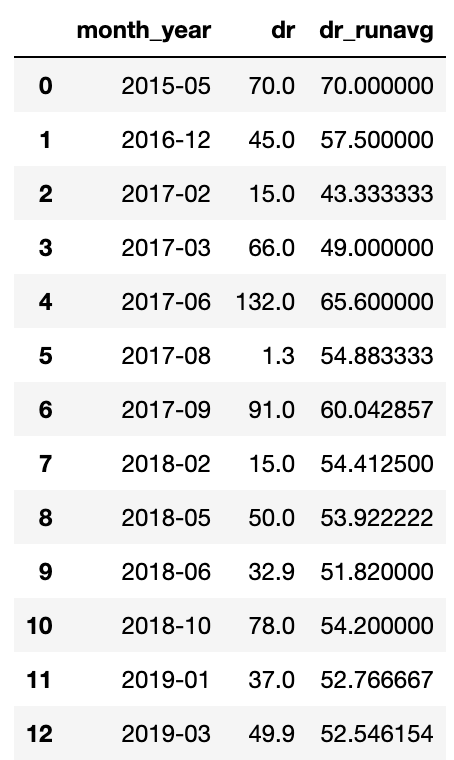
target_rd_mean_df = target_rd_cummean_df.groupby([‘month_year’])[‘dr’].sum().reset_index()
target_rd_mean_df[‘dr_runavg’] = target_rd_mean_df[‘dr’].expanding().mean()
target_rd_mean_df
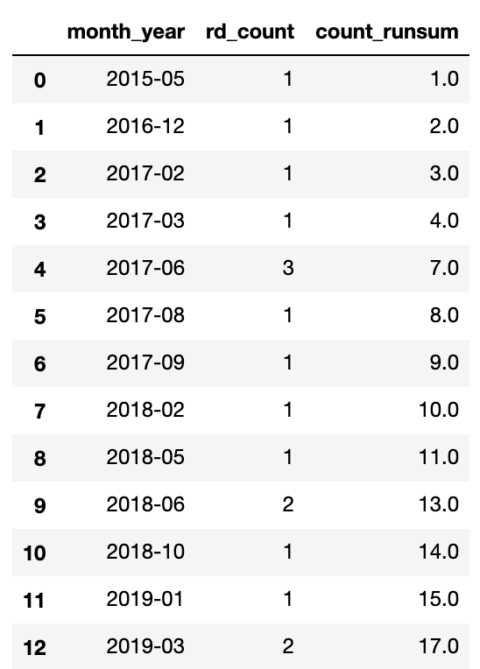 Pandas 截图,2022 年 3 月
Pandas 截图,2022 年 3 月
我们现在有一个表格,我们可以使用它来提供图表并将其可视化。
dr_cummean_smooth_plt = (
ggplot(target_rd_mean_df, aes(x = ‘month_year’, y = ‘dr_runavg’, group = 1)) +
geom_line(alpha = 0.6, color = ‘blue’, size = 2) +
scale_y_continuous() +
scale_x_date( ) +
theme(legend_position = ‘right’,
axis_text_x=element_text(rotation=90, hjust=1)
))
dr_cummean_smooth_plt
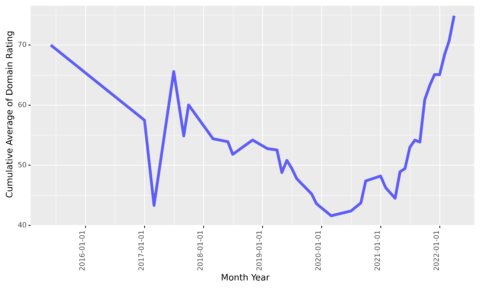 作者截图,2022 年 3 月
作者截图,2022 年 3 月
这很有趣,因为该网站似乎在其成立之初就开始吸引高权威的链接(可能是启动该业务的公关活动)。
然后它消失了四年,然后再次通过新的链接获取高权限链接重新出现。
链接量
写那个标题听起来不错!
谁不希望有大量(好)链接到他们的网站?
质量是一回事;音量是另一个,这是我们接下来要分析的。
与前面的操作非常相似,我们将使用扩展函数来计算迄今为止获得的链接的累积总和。
target_count_cumsum_df = target_ahrefs_analysis
target_count_cumsum_df = target_count_cumsum_df.groupby([‘month_year’])[‘rd_count’].sum().reset_index()
target_count_cumsum_df[‘count_runsum’] = target_count_cumsum_df[‘rd_count’].expanding().sum()
target_count_cumsum_df
Pandas 截图,2022 年 3 月
这是数据,现在是图表。
target_count_cumsum_plt = (
ggplot(target_count_cumsum_df, aes(x = ‘month_year’, y = ‘count_runsum’, group = 1)) +
geom_line(alpha = 0.6, color = ‘blue’, size = 2) +
scale_y_continuous() +
scale_x_date( ) +
theme(legend_position = ‘right’,
axis_text_x=element_text(rotation=90, hjust=1)
))
target_count_cumsum_plt
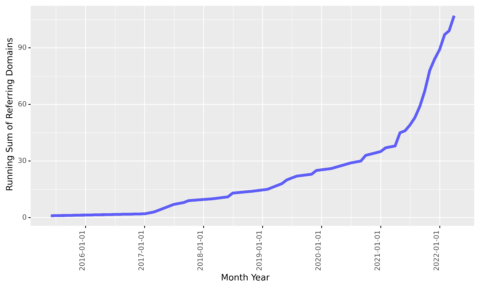 作者截图,2022 年 3 月
作者截图,2022 年 3 月
我们看到,在 2017 年初获得的链接有所放缓,但在接下来的四年中稳步增加,然后在 2021 年 3 月左右再次加速。
同样,最好将其与性能相关联。
更进一步
当然,以上只是冰山一角,因为它是对一个站点的简单探索。很难推断出任何有助于提高竞争性搜索空间排名的东西。
以下是进一步数据探索和分析的一些领域。
- 将社交媒体共享数据添加到两个目标 URL。
- 将整体站点可见性与随时间运行的平均 DR 相关联。
- 绘制 DR 随时间的分布。
- 在主机名上添加搜索量数据,以查看引用域收到多少品牌搜索,作为衡量真实权威的标准。
- 将爬网数据加入目标 URL 以测试内容相关性。
- 链接速度——从新站点获取新链接的速率。
- 将上述所有想法整合到您的分析中,以便与您的竞争对手进行比较。
我敢肯定上面没有列出很多想法,请随时在下面分享。



