每个网站都在一定程度上依赖谷歌。很简单:您的网页会被 Google 编入索引,这样人们就可以找到您。事情应该这样发展。
然而,情况并非总是如此。许多页面从未被谷歌索引。
如果您使用网站,尤其是大型网站,您可能已经注意到并非您网站上的每个页面都被编入索引,并且许多页面要等待数周才能被 Google 收录。
导致这个问题的因素有很多,其中许多因素与排名方面提到的因素相同——内容质量和链接就是两个例子。有时,这些因素也是非常复杂和技术性的。严重依赖新网络技术的现代网站过去曾因索引问题而臭名昭著,有些网站仍然存在。
许多谷歌搜索引擎优化仍然认为阻止谷歌索引内容的是非常技术性的东西,但这是一个神话。如果您没有就您希望将哪些网页编入索引或者您没有足够的抓取预算发送一致的技术信号,Google 确实可能不会将您的网页编入索引,但与您的内容质量保持一致同样重要。
大多数网站,无论大小,都有很多内容应该被编入索引——但事实并非如此。尽管 JavaScript 之类的东西确实使索引编制更加复杂,但您的网站可能会遇到严重的索引问题,即使它是用纯 HTML 编写的。在这篇文章中,让我们解决一些最常见的问题,以及如何缓解这些问题。
Google 未将您的网页编入索引的原因
使用自定义索引检查器工具,我检查了美国最受欢迎的电子商务商店的大量样本是否存在索引问题。我发现,平均而言,他们 15% 的可索引产品页面无法在 Google 上找到。
这个结果非常令人惊讶。接下来我需要知道的是“为什么”:谷歌决定不索引技术上应该被索引的东西的最常见原因是什么?
Google Search Console 报告未编入索引的页面的几种状态,例如“已抓取 – 当前未编入索引”或“已发现 – 当前未编入索引”。虽然此信息不能明确帮助解决问题,但它是开始诊断的好地方。
热门索引问题
根据我收集的大量网站样本,Google Search Console 报告的最常见的索引问题是:
1.“已抓取 – 当前未编入索引”
在这种情况下,Google 访问了一个页面,但没有将其编入索引。
根据我的经验,这通常是内容质量问题。鉴于目前正在发生的电子商务热潮,我们可以预期谷歌在质量方面会变得更加挑剔。因此,如果您发现您的页面“已被抓取 – 当前未编入索引”,请确保这些页面上的内容具有独特的价值:
-
在所有可索引的页面上使用唯一的标题、描述和副本。
-
避免从外部来源复制产品描述。
-
使用规范标签来合并重复的内容。
-
使用 robots.txt 文件或 noindex 标记阻止 Google 抓取您网站的低质量部分或将其编入索引。
如果您对该主题感兴趣,我建议您阅读 Chris Long 的 Crawled — Current Not Indexed: A Coverage Status Guide。
2.“已发现 – 目前未编入索引”
这是我最喜欢处理的问题,因为它可以涵盖从抓取问题到内容质量不足的所有问题。这是一个巨大的问题,特别是在大型电子商务商店的情况下,我已经看到这适用于单个网站上的数千万个 URL。
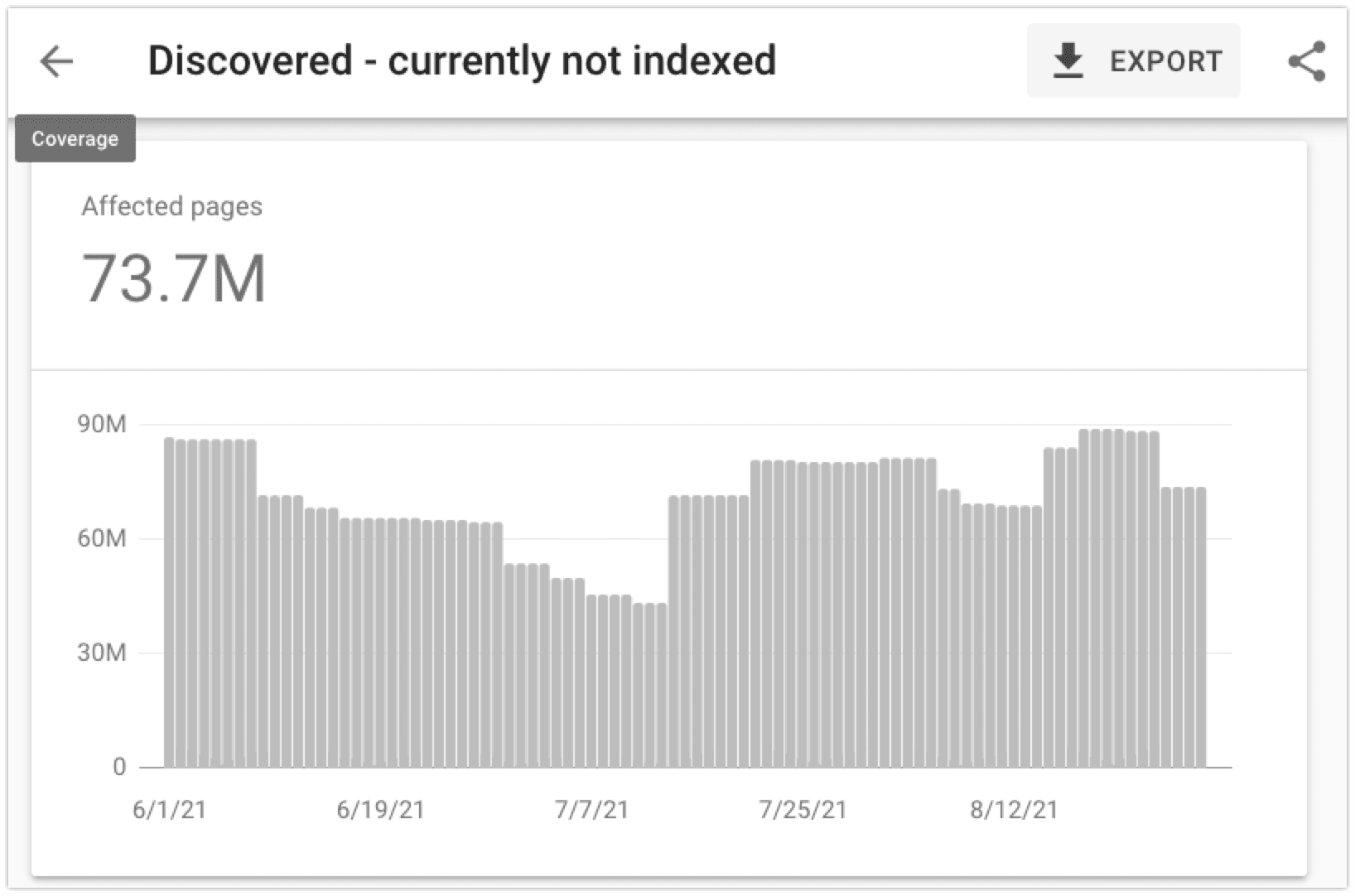
Google 可能会报告电子商务产品页面“已发现 – 当前未编入索引”,因为:
-
抓取预算问题:抓取队列中的 URL 可能过多,以后可能会抓取这些 URL 并编制索引。
-
质量问题:Google 可能认为该域中的某些页面不值得抓取,并通过在其 URL 中查找模式决定不访问它们。
处理这个问题需要一些专业知识。如果您发现您的页面是“已发现 – 当前未编入索引”,请执行以下操作:
-
确定是否有属于此类别的页面模式。也许问题与特定的产品类别有关,并且整个类别没有内部链接?或者可能有很大一部分产品页面正在排队等待被索引?
-
优化您的抓取预算。专注于发现谷歌花费大量时间抓取的低质量页面。通常的嫌疑人包括过滤的类别页面和内部搜索页面——这些页面在典型的电子商务网站上很容易进入数千万。如果 Googlebot 可以自由抓取它们,它可能没有资源来获取您网站上被 Google 索引的有价值的东西。
在“渲染 google SEO”网络研讨会期间,Google 的 Martin Splitt 给了我们一些关于修复 Discovered not indexed 问题的提示。如果您想了解更多信息,请查看它。
3.“重复内容”
Moz google SEO Learning Center 广泛涵盖了这个问题。在这里我只想指出,重复的内容可能是由多种原因造成的,例如:
-
语言变化(例如英国、美国或加拿大的英语)。如果您有针对不同国家/地区的同一页面的多个版本,则其中一些页面可能最终未编入索引。
-
竞争对手使用的重复内容。当多个网站使用制造商提供的相同产品描述时,这经常发生在电子商务行业。
除了使用 rel=canonical、301 重定向或创建独特的内容之外,我将专注于为用户提供独特的价值。Fast-growth-trees.com 就是一个例子。该网站不再是关于种植和浇水的无聊描述和提示,而是允许您查看许多产品的详细常见问题解答。
此外,您可以轻松地比较同类产品。
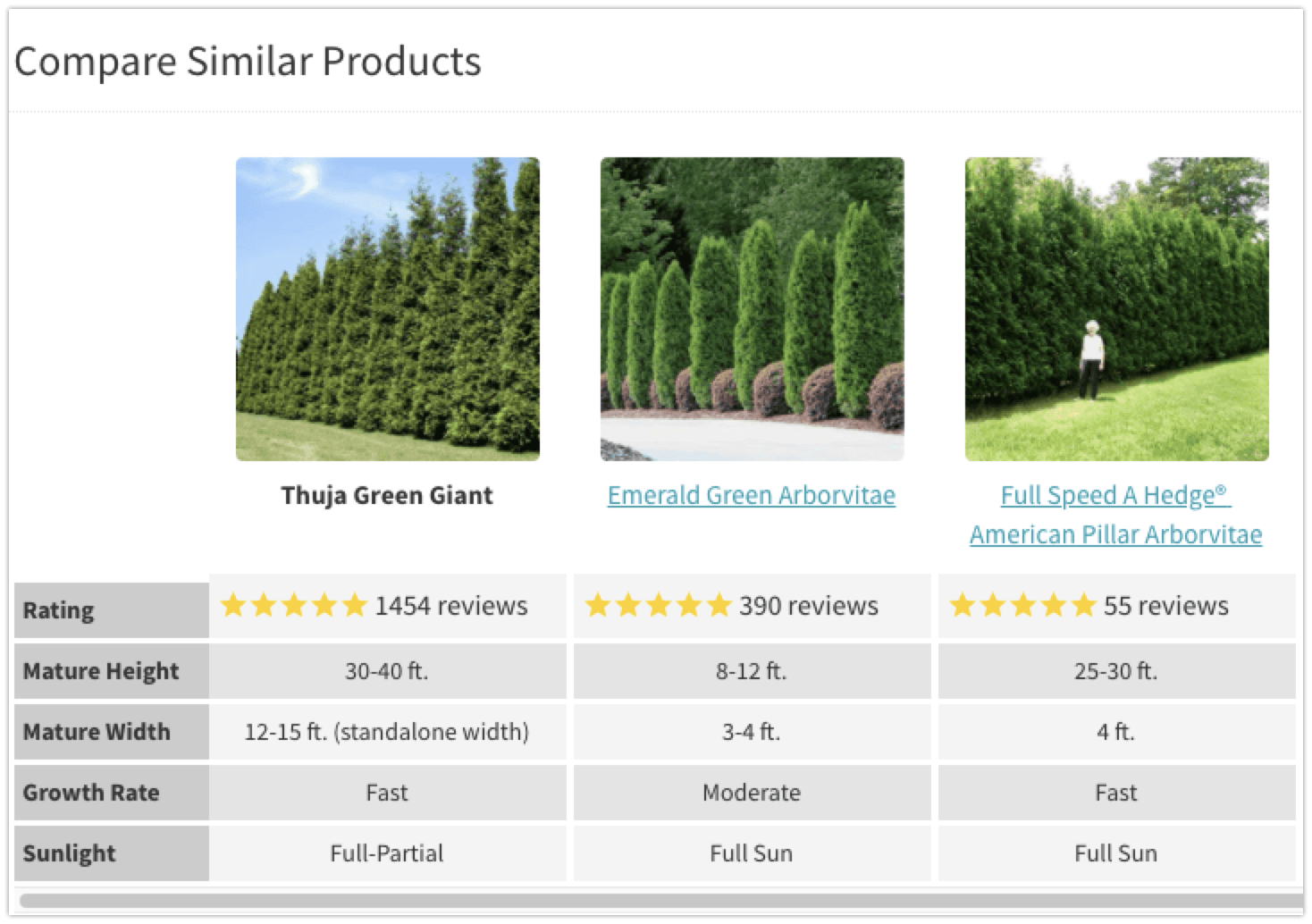
对于许多产品,它提供了一个常见问题解答。此外,每个客户都可以询问有关植物的详细问题并从社区中获得答案。
如何检查您网站的索引覆盖率
通过在 Google Search Console 中打开“索引覆盖率”报告,您可以轻松地检查您的网站有多少页面未被编入索引。
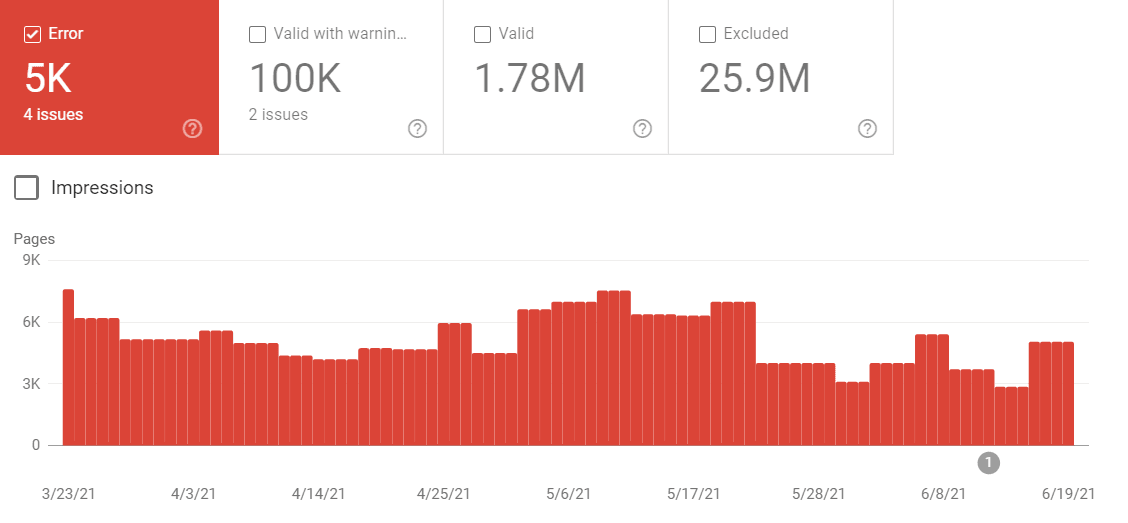
您应该在这里查看的第一件事是排除页面的数量。然后尝试找到一种模式——哪些类型的页面没有被索引?
如果您拥有一家电子商务商店,您很可能会看到未编入索引的产品页面。虽然这应该始终是一个警告信号,但您不能期望将所有产品页面都编入索引,尤其是对于大型网站。例如,大型电子商务商店必然会有重复的页面和过期或缺货的产品。这些页面可能缺乏将它们置于 Google 索引队列前面的质量(如果 Google 决定首先抓取这些页面)。
此外,大型电子商务网站往往存在抓取预算问题。我见过电子商务商店拥有超过一百万种产品的案例,其中 90% 被归类为“已发现 – 目前未编入索引”。但是,如果您看到重要页面被排除在 Google 的索引之外,您应该深感担忧。
如何增加 Google 将您的网页编入索引的可能性
每个网站都是不同的,并且可能会遇到不同的索引问题。但是,这里有一些可以帮助您的页面被索引的最佳实践:
1. 避免“Soft 404”信号
确保您的页面不包含任何可能错误地指示软 404 状态的内容。这包括从在副本中使用“未找到”或“不可用”到在 URL 中使用数字“404”的任何内容。
2.使用内部链接内部链接是谷歌的关键信号之一,即给定页面是网站的重要组成部分,值得被索引。在您的网站结构中不要留下孤立页面,并记住在您的站点地图中包含所有可索引的页面。
3. 实施完善的抓取策略不要让谷歌在你的网站上抓取垃圾。如果太多资源用于抓取您域中价值较低的部分,那么 Google 可能需要很长时间才能找到好东西。服务器日志分析可以让您全面了解 Googlebot 抓取的内容以及如何对其进行优化。
4.消除低质量和重复的内容每个大型网站最终都会出现一些不应该被索引的页面。确保这些页面不会进入您的站点地图,并在适当的时候使用 noindex 标记和 robots.txt 文件。如果您让 Google 在您网站最糟糕的部分花费太多时间,它可能会低估您的域的整体质量。
5.发送一致的谷歌搜索引擎优化信号。向 Google 发送不一致的 google SEO 信号的一个常见示例是使用 JavaScript 更改规范标签。正如 Google 的 Martin Splitt 在 JavaScript google SEO Office Hours 中提到的那样,如果您在源 HTML 中有一个规范标签,而在呈现 JavaScript 后有一个不同的标签,您永远无法确定 Google 会做什么。
网络变得太大了
在过去的几年里,谷歌在处理 JavaScript 方面取得了巨大的飞跃,使谷歌 SEO 的工作变得更容易。如今,由于 JavaScript 支持的网站由于使用的特定技术堆栈而未编入索引的情况已不常见。
但是我们是否可以期望与 JavaScript 无关的索引问题也会发生同样的情况?我不这么认为。
互联网不断发展。每天都有新网站出现,现有网站也在增长。
谷歌能否应对这一挑战?
这个问题每隔一段时间就会出现一次。我喜欢在这里引用谷歌:
“Google 的资源数量是有限的,因此当面对几乎无限数量的在线内容时,Googlebot 只能找到并抓取其中一部分内容。然后,在我们爬取的内容中,我们只能索引一部分。”
换句话说,谷歌只能访问网络上所有页面的一部分,而索引更小的部分。即使您的网站很棒,您也应该牢记这一点。
Google 可能不会访问您网站的每个页面,即使它相对较小。您的工作是确保 Google 能够发现和索引对您的业务至关重要的页面。



