很多时候,我们假设谷歌 SEO 最佳实践适用于任何行业,对抗任何竞争对手。但大多数最佳实践未经测试,可能并非在每种情况下都是“最佳”的。
我们都知道,在 2020 年奏效的策略不一定会在 2021 年发挥作用,因为 Core Web Vitals (CWV) 和其他信号都在前面洗牌。我们必须为我们的企业和客户做得更好。
我本质上是一个数据书呆子,在 15 年的谷歌 SEO 中留下了许多战斗伤痕。分析数千个本地 SERP 的想法听起来太有趣了,不能放弃。我发现了一些令人惊讶的相关性,同样重要的是,我建立了一个可以每季度更新一次的方法和数据集,以显示随时间的变化。
我分析了零售银行业的 50,000 多个 SERP,以便了解锁定期间排名和搜索行为的巨大变化。我们有很多银行网站的历史数据,因此比较 COVID 前后的数据比从头开始更容易。
我将在下面分享我是如何做到的。但首先,我想分享为什么我认为分享这类研究对谷歌 SEO 社区如此重要。
为什么要使用数据验证 google SEO 最佳实践?
这是成为谷歌搜索引擎优化的好时机。我们拥有令人惊叹的工具,可以收集比以往更多的数据。我们拥有繁荣的社区和优秀的基础培训材料。
然而,我们经常看到我们的工艺被提炼成被认为普遍正确的过度简化的“最佳实践”。但如果谷歌搜索引擎优化中有一个普遍真理,那就是没有普遍真理。最佳实践可能会被误解或过时,从而导致错失机会或对企业造成直接损害。
以 CWV 日益重要的重要性为例,谷歌 SEO 有机会(和义务)将事实与虚构区分开来。我们需要知道 CWV 是否会随着时间的推移影响排名以及影响程度,以便我们可以优先考虑我们的努力。
我们可以通过研究测试和验证最佳实践来单独和集体提升我们的谷歌搜索引擎优化游戏。它只需要一个好奇的头脑,正确的工具,以及接受结果而不是强行叙述的意愿。
未能验证最佳实践是谷歌搜索引擎优化从业者的责任,并表明不愿意挑战假设。根据我的经验,缺乏数据可能会导致高级利益相关者的意见比谷歌 SEO 专家的建议更有分量。
从提出正确的问题开始
真正的洞察力来自于组合来自多个来源的数据以回答关键问题并确保您的策略得到有效数据的支持。在我对当地银行的分析中,我首先列出了我想知道答案的问题:
- 顶级本地银行网站有哪些共同特点?
- 银行实际上在 SERP 中与谁竞争?主要是其他银行吗?
- 竞争性 SERPS 如何根据用户搜索的时间/地点/方式发生变化?
- 较小的本地企业如何才能在本地区以外的较大竞争对手中获得优势?
- SERP 组合如何影响银行对目标关键字的良好排名能力?
- Core Web Vitals (CWV) 对排名有多重要?随着时间的推移,这将如何变化?
您可以通过将“银行”替换为其他本地业务类别来运行相同的分析。潜在问题的列表是无穷无尽的,因此您可以根据自己的需要进行调整。
这里有一个重要的提醒——准备好接受答案,即使它们没有结论或与你的假设相矛盾。如果我们要保持客观,数据驱动的谷歌搜索引擎优化必须避免确认偏差。
以下是我在几个小时内分析 50,000 个搜索结果的方法
我结合了我最喜欢的三个工具来大规模分析 SERP 并收集回答我的问题所需的数据:
- STAT 为选定的关键字生成排名报告
- Screaming Frog 抓取网站并收集技术谷歌 SEO 数据
- Power BI 分析大型数据集并创建简单的可视化
第 1 步:确定您的数据需求
我使用美国人口普查局的数据来识别所有人口超过 100,000 的城市,因为我想要代表全国各地的本地银行 SERP。我的列表最终包括 314 个不同的城市,但您可以自定义列表以满足您的需求。
我还想为桌面和移动搜索收集数据,以比较设备类型之间的 SERP 差异。
第 2 步:确定您的关键字
我选择了“我附近的银行”和“{city, st} 中的银行”,因为它们具有强烈的本地意图和高搜索量,与银行服务的更具体的关键字相比。
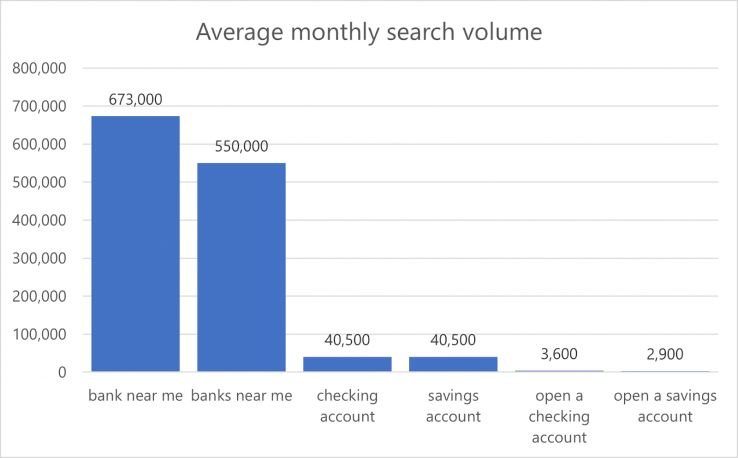
第 3 步:生成 .csv 格式的 STAT 导入文件
获得关键字和市场列表后,就可以为 STAT 准备批量上传了。使用链接中提供的模板创建一个包含以下字段的 .csv 文件:
- 项目:新 STAT 项目或现有项目的名称。
- 文件夹:新文件夹或现有文件夹的名称。(这是一个可选列,您可以留空。)
- 站点:您要跟踪的站点的域名。请注意,出于我们的目的,您可以在此处输入要跟踪的任何 URL。前 20 名报告将包括目标关键字的所有排名 URL,即使它们未列在您的“网站”列中。
- 关键字:您要添加的搜索查询。
- 标签:输入任意数量的关键字标签,以逗号分隔。我使用“城市”和“我附近”作为标签来区分查询类型。(这是一个可选列,您可以留空。)
- 市场:指定您要跟踪关键字的市场(国家和语言)。我用“US-en”表示美国英语。
- 位置:如果您想在特定位置跟踪关键字,请指定城市、州、省、邮政编码和/或邮政编码。我使用了“city, st”格式的城市和州列表。
- 设备:选择您想要桌面还是智能手机结果。我两个都选了。
每个市场、位置和设备类型都会使您必须跟踪的关键字数量成倍增加。我最终在我的导入文件中有 1,256 个关键字(314 个市场 X 2 个关键字 X 2 个设备)。

文件完成后,您可以导入 STAT 并开始跟踪。
第 4 步:在 STAT 中为所有关键字运行前 20 名报告
STAT 的内置 Google SERP 前 20 名比较报告以不同的时间间隔(每天、每周、每月等)捕获每个 SERP 的前 20 个有机结果,以查看随时间的变化。我不需要每天的数据,所以我只是让它连续两天运行并删除我不需要的数据。我每季度重新运行一次相同的报告,以跟踪一段时间内的变化。
观看下面的视频,了解如何设置此报告!
我的 1,256 个关键字每天生成超过 25,000 行数据。每行是一个不同的自然列表,包括关键字、每月搜索量、排名(包括本地包)、基本排名(不包括本地包)、排名 URL 的 https/http 协议、排名 URL 和您的标签。
以下是 CSV 格式的原始输出示例:
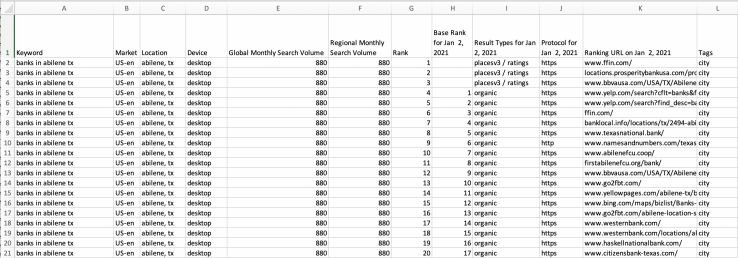
很容易看出这些数据本身有多么有用,但是当我们清理它并开始抓取排名 URL 时,它变得更加强大。
第 5 步:清理和规范化您的 STAT URL 数据
此时,您可能已经投入 1-2 小时来收集初始数据。这一步有点费时,但数据清理可以让您在 Screaming Frog 中运行更高级的分析并发现更多有用的见解。
以下是我对 STAT 排名数据所做的更改,为 Screaming Frog 和 Power BI 中的后续步骤做准备。您最终会得到多列 URL。每个稍后都有一个目的。
- 将 Ranking URL 列复制到一个名为 Normalized URL 的新列。
- 通过使用 Excel 的文本到列工具并用“?”分隔,从规范化 URL 字段中删除 URL 参数。我删除了包含 URL 参数的新列,因为它们对我的分析没有帮助。
- 将新的、干净的规范化 URL 列复制到名为 TLD 的新列中。使用 TLD 列上的文本到列工具并用“/”分隔以删除除域名和子域之外的所有内容。删除新列。我选择将子域保留在我的 TLD 列中,但如果它有助于您的分析,您可以将其删除。
- 最后,再创建一个名为 Full URL 的列,该列最终将成为您将在 Screaming Frog 中抓取的 URL 列表。要生成完整 URL,只需使用 Excel 的连接函数来组合协议和规范化 URL 列。您的公式将如下所示: =concatenate(A1, “://”, C1) 在有效的 URL 字符串中包含“://”。
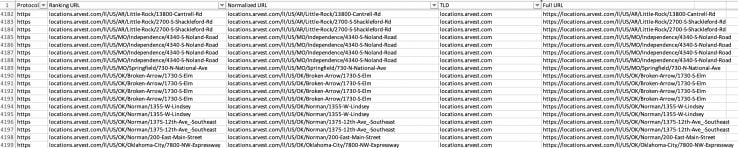
我的数据集中的 25,000 多行完全在 Excel 的限制范围内,因此我能够在一个地方轻松地操作数据。随着数据集的增长,您可能需要使用数据库(我喜欢 BigQuery)。
第 6 步:按网站类型对 SERP 结果进行分类
浏览 SERP 结果,很容易看出银行并不是唯一一种对具有本地搜索意图的关键字进行排名的网站。由于我最初的问题之一是 SERP 组合,因此我必须识别所有不同类型的网站并标记每个网站以进行进一步分析。
这一步是迄今为止最耗时和最有见地的。我花了 3 个小时将最初的 25,000 多个 URL 分类为以下类别之一:
- 机构(银行和信用合作社网站)
- 目录(聚合器、本地业务目录等)
- 评论(本地和国家网站,如 Yelp.com)
- 教育(.edu 域上有关银行的内容)
- 政府(.gov 域和市政网站上有关银行的内容)
- 工作(职业网站和工作聚合器)
- 新闻(具有银行内容的本地和国家新闻网站)
- 食品银行(是的,很多食品银行在“我附近的银行”关键字中排名)
- 房地产(商业和住宅房地产清单)
- 搜索引擎(属于搜索引擎的排名内容)
- 社交媒体(社交媒体网站上的排名内容)
- 其他(与上述任何一项无关的完全随机结果)
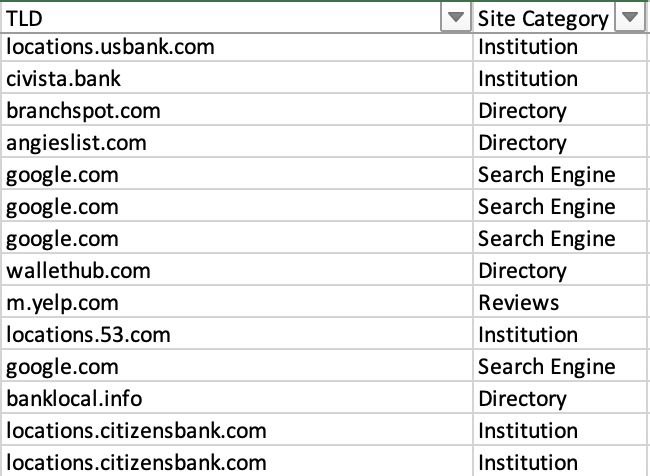
您当地的 SERP 可能包含许多此类网站类型和其他不相关的类别,例如食品银行。通过对 TLD 和规范化 URL 列进行排序和过滤以同时对多行进行分类,从而加快流程。例如,可以通过快速复制/粘贴将所有 yelp.com 排名归类为“评论”。
至此,您的排名数据集已完成,您可以开始爬取行业中排名靠前的网站,看看它们有什么共同点。
第 7 步:使用 Screaming Frog 抓取您的目标网站
我最初的 STAT 数据确定了来自本地银行网站的 6,600 多个独特页面,这些页面在前 20 个自然搜索结果中排名。这是太多页面,无法手动评估。输入 Screaming Frog,一个模仿谷歌网络爬虫并从网站中提取大量谷歌 SEO 数据的爬虫。
我将 Screaming Frog 配置为抓取 6,600 个排名页面中的每一个,以便对排名靠前的银行网站共享的特征进行更广泛的分析。不要只是让SF松动。请务必正确配置它以节省时间并避免爬取不必要的页面。
这些设置可确保我们一次性获得回答问题所需的所有信息:
列表模式:粘贴从您的 STAT 数据中删除重复的完整 URL 列表。就我而言,这是 6,600 多个 URL。

数据库存储模式:它可能比内存 (RAM) 存储慢一点,但将爬取结果保存在硬盘上可确保如果您犯了错误(就像我犯了很多次)并关闭您的报告,您不会丢失结果在完成数据分析之前。
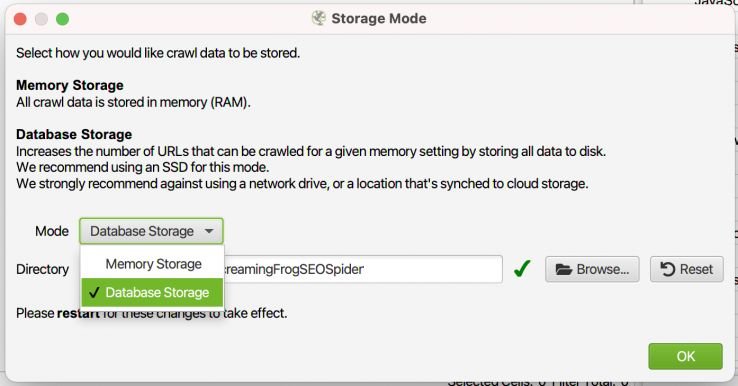
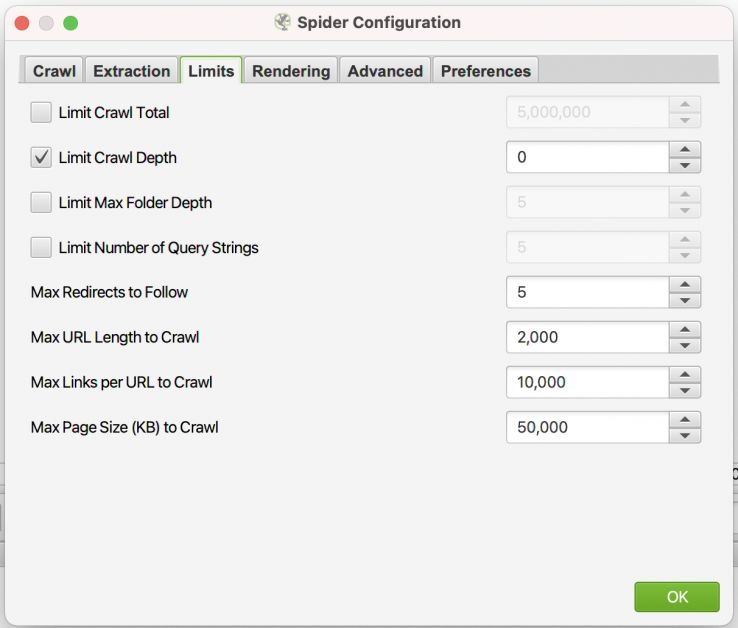
限制抓取深度:将此设置为 0(零),这样蜘蛛只会抓取您列表中的 URL,而不会跟踪指向这些域上其他页面的内部链接。
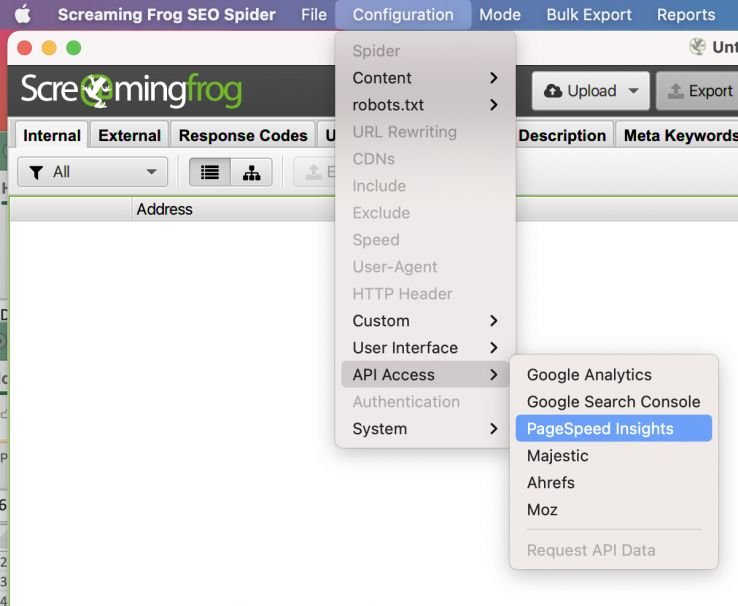
API:我强烈建议使用 Pagespeed Insights Integration 将 Lighthouse 速度指标直接提取到您的爬网数据中。如果您有一个具有 API 访问权限的 Moz 帐户,您还可以通过内置集成从 Moz API 中提取链接和域数据。
一旦你配置了蜘蛛,让它撕裂!这可能需要几分钟到几个小时,具体取决于您要抓取的 URL 数量以及计算机的速度和内存限制。耐心一点!您可以尝试在一夜之间或在额外的计算机上运行更大的爬网,以避免让您的主机陷入困境。
第 8 步:将 Screaming Frog 爬行数据导出到 Excel
将爬网数据转储到 Excel 中非常容易。
步骤 9:在 Power BI 中加入数据集
此时,您应该在 Excel 中有两个数据源:一个用于您的 STAT 排名数据,另一个用于您的 Screaming Frog 爬行数据。我们的目标是结合这两个数据源,以了解自然搜索排名如何受页面上 google SEO 元素和网站性能的影响。为此,我们必须首先合并数据。
如果您可以使用 Windows PC,Power BI 的免费版本足以让您入门。首先使用获取数据向导将您的两个数据源加载到一个新项目中。
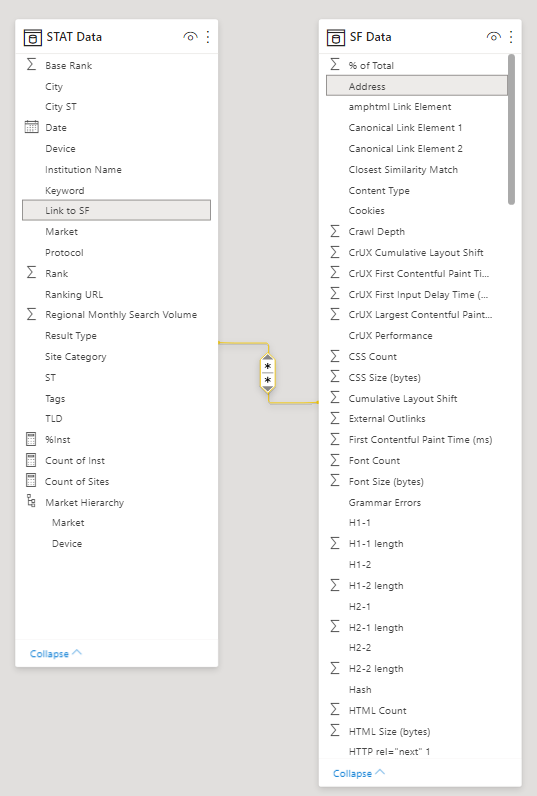
加载数据集后,就可以通过在数据中创建关系来解锁排名和网站特征之间的相关性,从而创造奇迹。若要在 Power BI 中组合数据,请在 STAT 完整 URL 和 Screaming Frog 原始 URL 字段之间创建多对多关系。
如果您不熟悉 BI 工具和数据可视化,请不要担心!只需快速搜索即可找到许多有用的教程和视频。在这一点上,真的很难打破任何东西,您可以尝试多种方法来分析数据并与多种类型的图表和图形分享见解。
我应该注意到,Power BI 是我首选的数据可视化工具,但您也许可以使用 Tableau 或其他同样强大的工具。Google Data Studio 不是此分析的一个选项,因为它只允许多个数据源的左外连接,并且不支持“多对多”关系。这是一种技术上的说法,Data Studio 不够灵活,无法创建我们需要的数据关系。
第 10 步:分析和可视化!
Power BI 的内置可视化让你可以快速汇总和呈现数据。这是我们可以开始分析数据以回答我们之前提出的问题的地方。
结果——我们学到了什么?
以下是通过合并我们的排名和抓取数据收集的见解的几个示例。剧透警报 – CWV 不会强烈影响自然排名……但是!
银行实际上在 SERP 中与谁竞争?主要是其他银行吗?
在台式机上,约 67% 的自然搜索结果属于金融机构(银行和信用合作社),来自评论网站 (7%) 和在线目录 (22%) 的激烈竞争。这些信息通过展示监控和维护相关目录和评论网站中的列表的机会,帮助塑造我们针对银行的谷歌 SEO 策略。
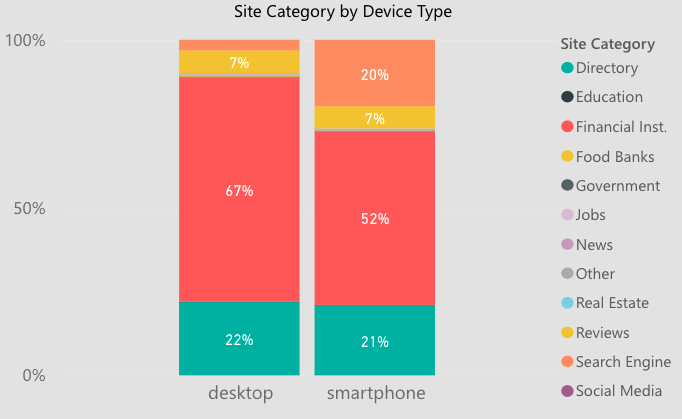
好的,现在让我们混合我们的数据源,看看网站类别的分布如何随桌面设备上的排名而变化。突然间,我们可以看到金融机构实际上占据了前 3 名结果的大部分,而评论网站和目录在第 4-10 位中更为普遍。
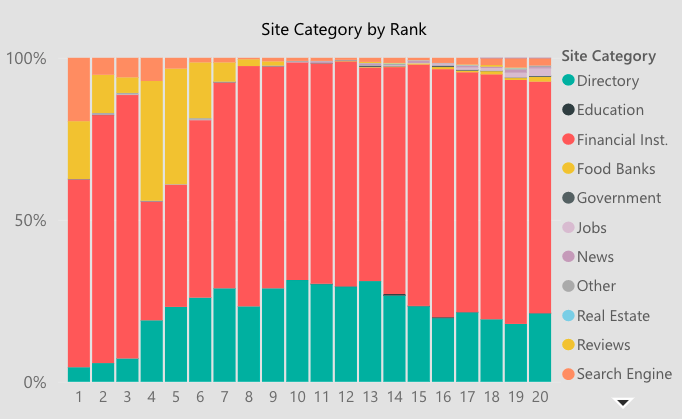
Core Web Vitals (CWV) 对排名有多重要?随着时间的推移,这将如何变化?
网站性能和网站速度是 google SEO 中的热门话题,随着 CWV 在今年 5 月成为排名信号,它只会变得更加重要。我们可以通过比较 STAT 排名和 Screaming Frog 报告中的 Pagespeed Insights 数据来开始了解网站速度和排名之间的关系。
截至 2021 年 1 月,Lighthouse 性能得分较高(即加载速度更快)的站点往往比得分较低的站点排名更好。这可能有助于证明对站点速度和站点性能的投资是合理的。
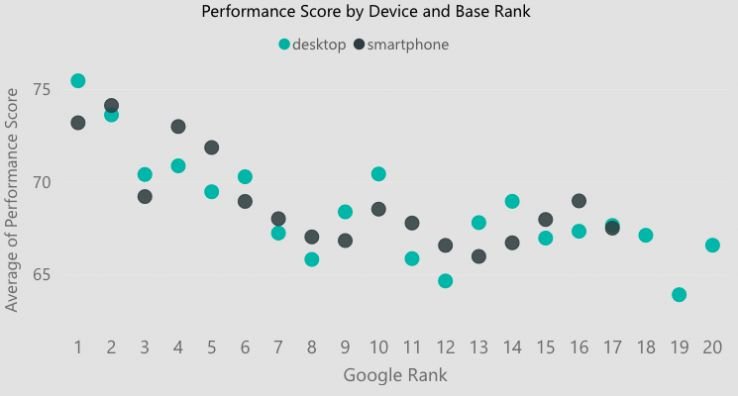
一些 CWV 元素与更好的排名相关性更密切,而其他元素则更加分散。这并不是说 CWV 不重要或没有意义,而是说它是 5 月之后进一步分析的起点。
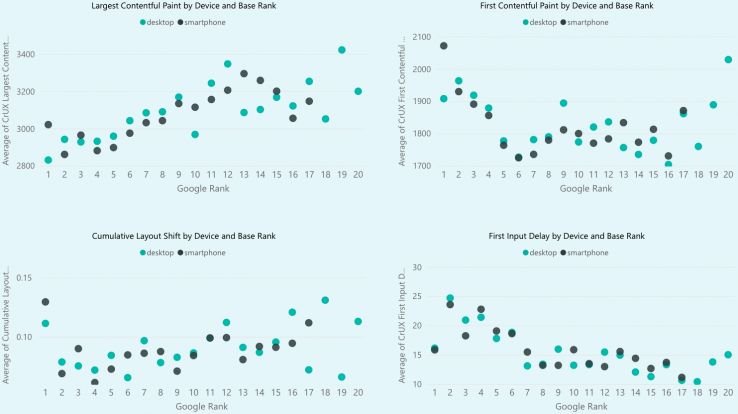
所以呢?我们可以从这种类型的分析中学到什么?
另外,STAT 和 Screaming Frog 是非常强大的谷歌 SEO 工具。如果您碰巧是 google SEO,他们提供的数据很有用,但是合并数据和提取关系的能力将使您在任何重视数据并根据洞察力采取行动的组织中的价值成倍增长。
除了用数据验证一些普遍接受的谷歌搜索引擎优化知识(“更快的网站获得更好的排名”),更好地使用关系数据还可以帮助我们避免将宝贵的时间花在不太重要的策略上(“不惜一切代价改善累积布局转换!” )。
当然,相关性并不意味着因果关系,汇总数据并不能保证单个站点的结果。但是,如果您是负责从自然渠道获取客户的银行营销专业人士,则需要将此类数据提供给您的利益相关者,以证明增加对 google SEO 的投资是合理的。
通过分享工具和方法,我希望其他人能够通过构建并将他们的额外发现贡献给 google SEO 社区来进一步发展。我们可以结合哪些其他数据集来在更大范围内加深对 SERP 的理解?在评论中让我知道你的想法!



