
在任何领域做出的最困难的决定之一就是有意识地选择错过最后期限。在过去的几个月里,由一些最聪明的工程师、数据科学家、项目经理、编辑和营销人员组成的团队一直在努力争取在 2020 年 9 月 30 日发布新的 Page Authority (PA)。新模型非常出色几乎在所有方面都与当前的 PA 不同,但我们最后的质量控制措施揭示了一个我们不能忽视的异常情况。
因此,我们做出了推迟发布 Page Authority 2.0 的艰难决定。所以,让我花点时间回顾一下我们是如何到达这里的,离开我们的地方,以及我们打算如何进行。
用新的眼光看老问题
从历史上看,Moz 一遍又一遍地使用相同的方法来构建页面权限模型(以及域权限)。这个模型的优点是它的简单性,但它还有很多不足之处。
Previous Page Authority 模型针对 SERP 进行了训练,试图根据从 Link Explorer 反向链接索引计算的一组链接指标来预测一个 URL 是否会高于另一个 URL。这种模型的一个关键问题是它无法有意义地解决一组特定链接度量的最大强度。
例如,想象一下 Internet 上最强大的链接 URL:Google、Youtube、Facebook 的主页,或者被关注的社交网络按钮的分享 URL。没有任何 SERP 可以将这些 URL 相互竞争。相反,这些极其强大的 URL 通常排名第一,然后是指标低得多的页面。想象一下,如果迈克尔乔丹、科比布莱恩特和勒布朗詹姆斯各自与高中球员进行一对一的比赛。每次都会赢。但是我们很难从这些结果中推断出迈克尔·乔丹、科比·布莱恩特或勒布朗·詹姆斯是否会在一对一的比赛中获胜。
在重新审视域权限的任务时,我们最终选择了一个我们拥有丰富经验的模型:原始的 SERP 训练方法(尽管进行了一些调整)。借助 Page Authority,我们决定完全采用不同的训练方法,通过预测哪个页面将拥有更多的总有机流量。该模型展示了一些有希望的品质,例如能够比较不在同一个 SERP 上出现的 URL,但也存在其他困难,例如具有高链接资产但只是处于不常搜索的主题区域的页面。我们解决了其中许多问题,例如增强训练集,以使用非链接度量来解释竞争力。
衡量新页面权限的质量
结果是——而且是——非常有希望。
首先,新模型显然预测了一个页面比另一个页面拥有更有价值的自然流量的可能性。这是意料之中的,因为新模型是针对这个特定目标的,而当前的 Page Authority 只是试图预测一个页面是否会排在另一个页面之上。
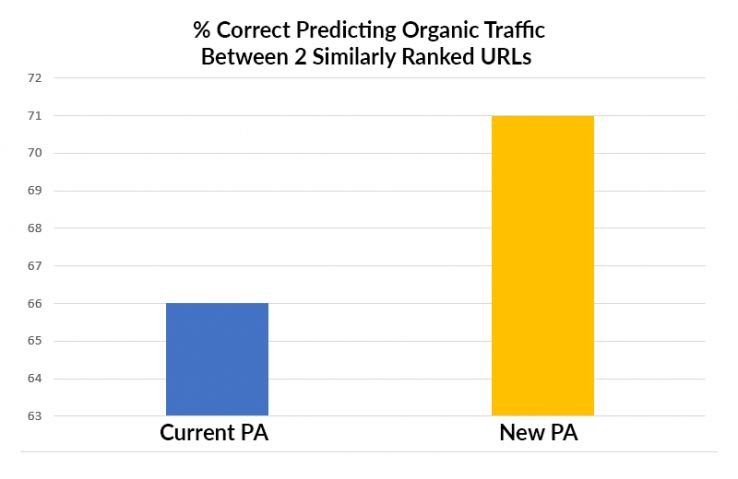
其次,我们发现新模型可以预测一个页面的排名是否会比之前的页面权限更好。这特别令人高兴,因为它消除了我们的许多担忧,即由于新的训练模型,新模型将在旧的质量控制方面表现不佳。
新模型在预测 SERP 方面比当前 PA 好多少?在每个间隔——一直到第 4 对 5 的位置——新模型都与当前模型并列或优于当前模型。它从未丢失过。
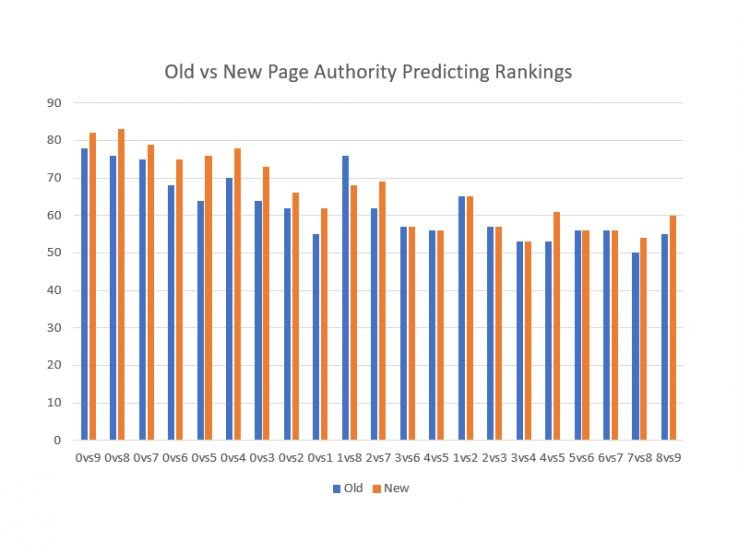
一切看起来都很棒。然后我们开始分析异常值。我喜欢称其为“有什么看起来很愚蠢吗?” 测试。机器学习会犯错误,就像人类一样,但人类倾向于以非常特殊的方式犯错误。当一个人犯错时,我们通常会准确地理解为什么会犯错。机器学习并非如此,尤其是神经网络;我们在新模型下提取了具有高页面权限的 URL,这些 URL 恰好具有零有机流量,并将它们包含在训练集中以学习这些错误。我们很快看到奇怪的 90+ PA 下降到更合理的 60 年代和 70 年代……又一次胜利。
我们进行了最后一次测试。
品牌搜索的问题
网络上一些最流行的关键字是导航性的。人们在 Google 上搜索 Facebook、Youtube,甚至 Google 本身。相对于其他关键字,这些关键字被搜索了天文数字。随后,少数强大的品牌可以对将总搜索量作为其核心培训目标的一部分的模型产生巨大影响。
最后一个测试涉及将当前的页面权限与新的页面权限进行比较,以确定是否存在任何奇怪的异常值(其中 PA 急剧变化且没有明显原因)。首先,让我们看一下 Linking Root Domains 的 LOG 与 Page Authority 的简单对比。
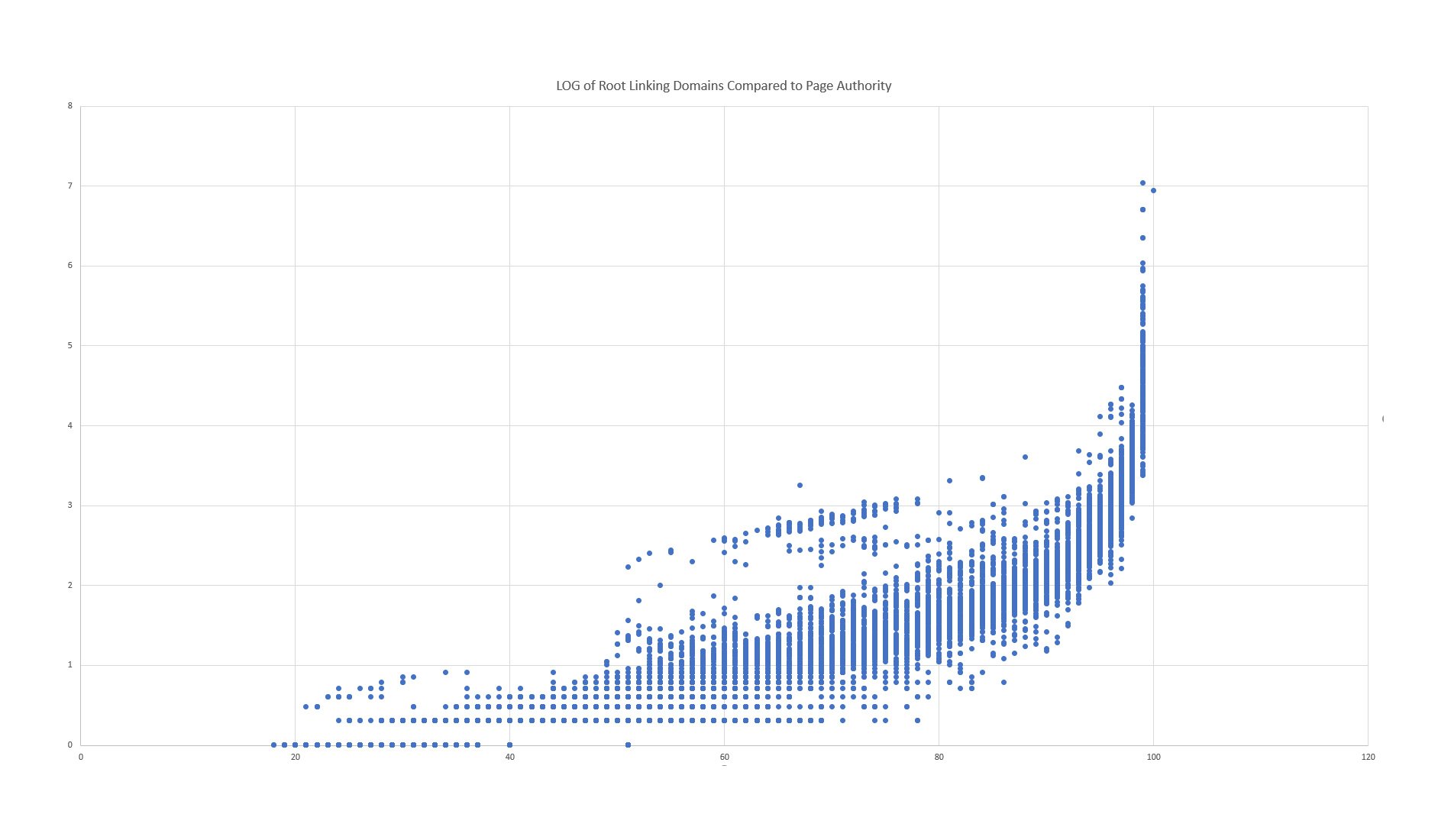
不是太寒酸。我们看到链接根域和页面权限之间通常呈正相关。但是你能发现其中的怪事吗?来吧,花点时间……
这张图表中有两个异常突出:
- URL 的主要分布与上方和下方的异常值之间存在一个奇怪的差距。
- 单个分数的最大差异是 PA 99。有大量的 PA 99 具有广泛的链接根域。
这是一个有助于找出这些异常的可视化:
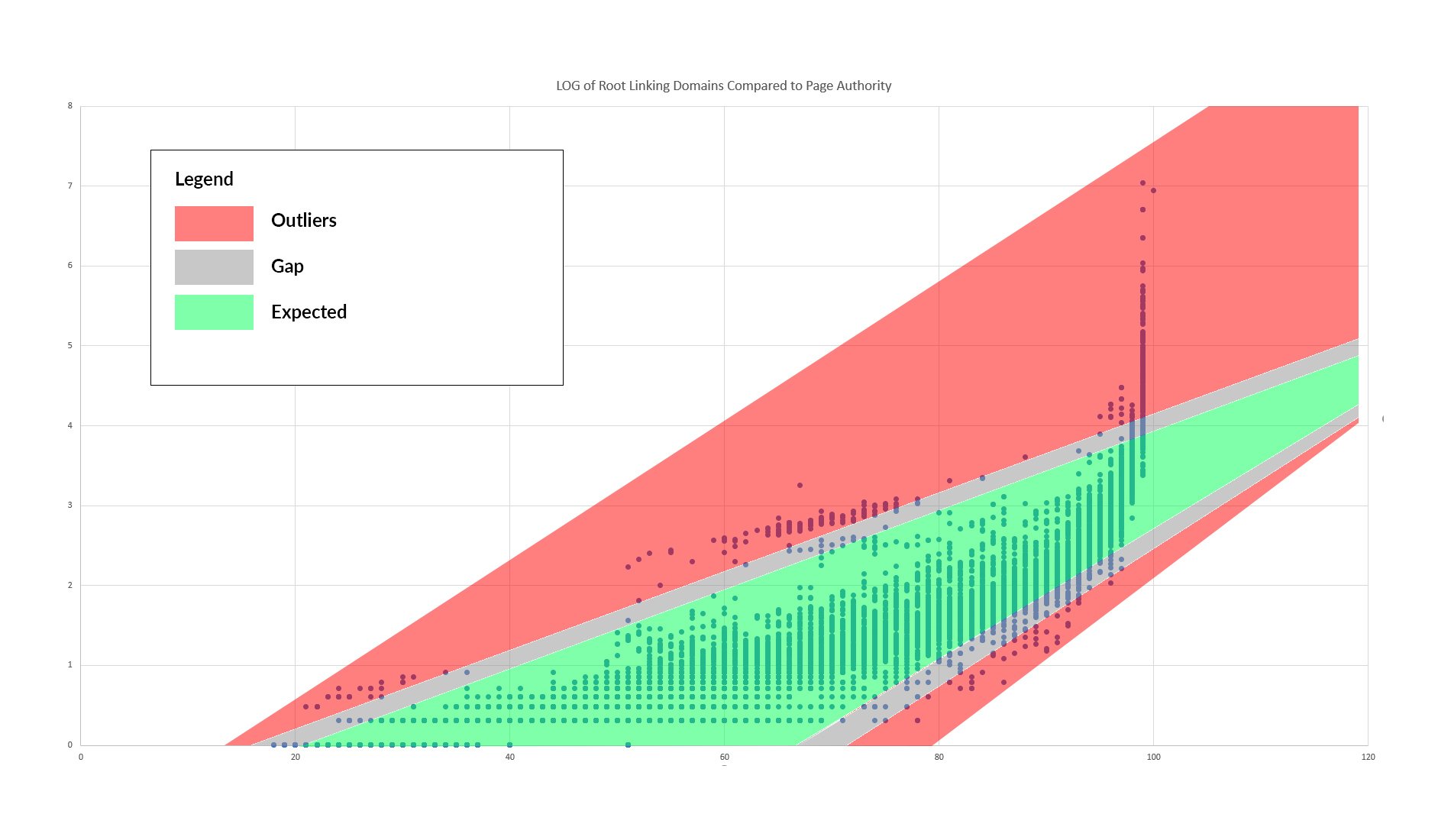
绿色和红色之间的灰色空间代表了大部分分布和异常值之间的奇怪差距。异常值(红色)倾向于聚集在一起,尤其是在主要分布之上。当然,我们可以看到 PA 99 顶部的分布很差。
请记住,这些问题不足以使新的 Page Authority 模型不如当前模型准确。然而,经过进一步检查,我们发现该模型确实产生的错误非常严重,以至于它们可能会对我们客户的决策产生不利影响。最好有一个模型在任何地方都有一点偏差(因为谷歌 SEO 所做的调整并没有令人难以置信的微调),而不是一个几乎在任何地方都正确但在少数情况下奇怪错误的模型。幸运的是,我们对问题所在相当有信心。似乎主页 PA 被过度夸大了,可能的罪魁祸首是训练集。在我们完成再培训之前,我们无法确定这就是原因,但这是一个强大的领先优势。
好消息和坏消息
就我们有多个优于现有页面权限的候选模型而言,我们处于良好状态。我们正处于消除错误的地步,而不是模型构建。但是,在我们确信它将引导我们的客户朝着正确的方向前进之前,我们不会发布新的分数。我们高度重视客户根据我们的指标做出的决定,而不仅仅是指标是否符合某些统计标准。
鉴于所有这些,我们决定推迟发布 Page Authority 2.0。这将为我们提供必要的时间来解决这些主要问题并产生出色的指标。令人沮丧?是的,但也是必要的。
与往常一样,我们感谢您的耐心等待,我们期待生成我们发布过的最佳页面权限指标。
访问 PA 资源中心



