
本博客中引用的 YouTube 播放列表可在此处找到:6 部分 YouTube 系列 [设置和使用查询优化检查器]
任何将谷歌搜索引擎优化作为其工作的一部分的人都知道,分析哪些查询是和不向网站上的特定页面发送流量是很有价值的。
这些数据集最常见的用途是将页面优化与现有排名和流量保持一致,并确定排名关键字的差距。
但是,处理这些数据非常乏味,因为它只能在 Google Search Console 界面中使用,而且您一次只能查看一页。
最重要的是,要获取有关排名页面中包含的文本的信息,您需要手动查看它或使用 Screaming Frog 之类的工具提取它。
您需要这种视图:
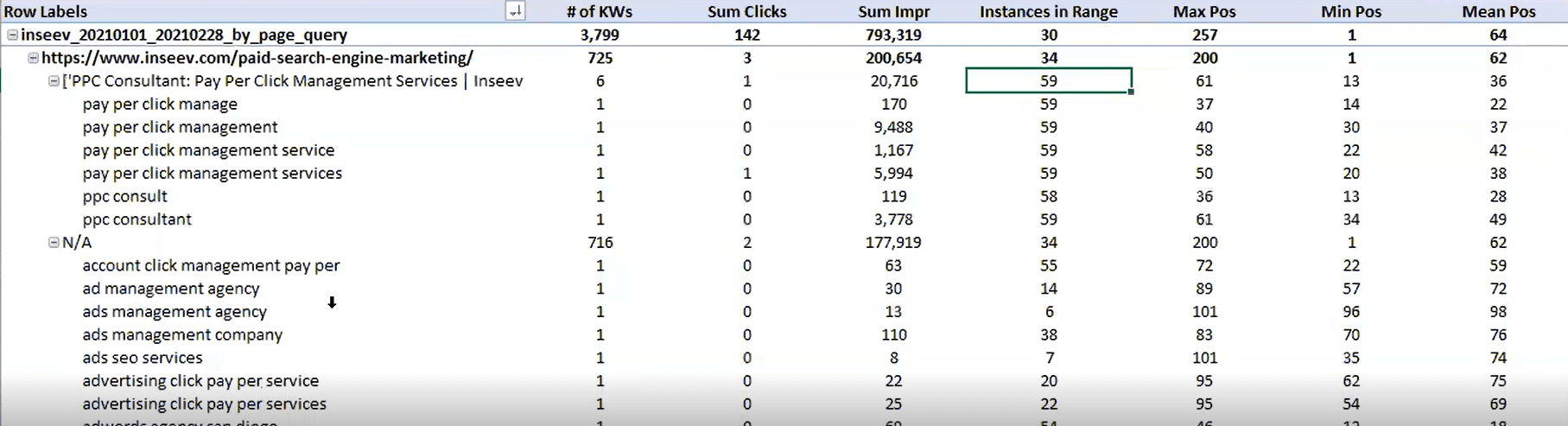
…但即使是上述视图一次也只能是一页,并且如前所述,实际的文本提取也必须是分开的。
鉴于 google SEO 社区可随时使用的数据存在这些明显问题,Inseev Interactive 的数据工程团队一直在思考如何大规模改进这些流程。
我们将在这篇文章中讨论的一个具体示例是一个简单的脚本,它允许您以灵活的格式获取上述数据,从而获得许多出色的分析视图。
更好的是,这一切都只需要几个单一的输入变量。
工具功能的快速概述
该工具会自动将页面上的文本与页面级别的 Google Search Console 热门查询进行比较,让您知道哪些查询在页面上以及它们在页面上出现的次数。可选的 XPath 变量还允许您指定要分析文本的页面部分。
这意味着您将确切地知道哪些查询正在推动不在您的 <title>、<h1> 或什至与主要内容 (MC) 中的第一段一样具体的点击/印象。天空是极限。
对于那些不熟悉的人,我们还提供了一些您可以使用的快速 XPath 表达式,以及如何在文章的“输入变量”部分中创建特定于站点的 XPath 表达式。
后期设置使用和数据集
设置流程后,只需填写一个简短的变量列表,其余的将为您自动完成。
输出数据集包括多个自动化的 CSV 数据集,以及结构化的文件格式,以使事情井井有条。核心分析自动化 CSV 的一个简单支点可以为您提供以下数据集和许多其他有用的布局。
……甚至是一些“新指标”?
好吧,从技术上讲,这不是“新”,但如果您专门使用 Google Search Console 用户界面,那么您以前可能无法访问以下指标:“最大位置”、“最小位置”和“计数位置”指定的日期范围——所有这些都在帖子的“运行您的第一次分析”部分中进行了解释。

为了真正展示这个数据集的影响和有用性,在下面的视频中,我们使用 Colab 工具来:
- [3 分钟] — 为 https://www.inseev.com/ 寻找非品牌 <title> 优化机会(视频大约 30 页,但您可以做任意数量的页面)
- [3 分钟] — 将 CSV 转换为更可用的格式
- [1 分钟] – 使用结果数据集优化第一个标题
好的,您已准备好进行初始概要。希望我们能够在进入有点沉闷的设置过程之前让您感到兴奋。
请记住,在帖子的末尾,还有一个部分包括一些有用的用例和示例模板!要直接跳转到这篇文章的每个部分,请使用以下链接:
- 在 Google Colab 中一次性设置脚本
- 运行您的第一个分析
- 实际用例和模板
[快速考虑 #1] — 该工具中内置的网络爬虫不支持 JavaScript 渲染。如果您的网站使用客户端渲染,那么该工具的全部功能将无法正常工作。
[快速考虑 #2] — 该工具已经过 Inseev 团队成员的大量测试。大多数错误(特别是网络爬虫)已被发现并修复,但与任何其他程序一样,可能会出现其他问题。
- 如果您遇到任何错误,请随时通过 jmelman@inseev.com 或 info@inseev.com 直接与我们联系,我本人或 Inseev 数据工程团队的其他成员将很乐意为您提供帮助.
- 如果遇到并修复了新错误,我们将始终将更新的脚本上传到以下部分链接的代码存储库,以便所有人都可以使用最新的代码!
在 Google Colab 中一次性设置脚本(不到 20 分钟)
你需要的东西:
- 谷歌云端硬盘
- 谷歌云平台帐号
- 谷歌搜索控制台访问
视频演练:工具设置过程
您将在下面找到分步编辑说明,以设置整个过程。但是,如果您不喜欢遵循编辑说明,我们也会录制设置过程的视频。
正如您将看到的,我们从一个全新的 Gmail 开始,并在大约 12 分钟内设置了整个过程,并且输出完全值得花时间。
请记住,设置是一次性的,一旦设置,该工具应该从那里开始使用命令!
编辑演练:工具设置过程
四部分流程:
- 从 Github 下载文件并在 Google Drive 中设置
- 设置 Google Cloud Platform (GCP) 项目(如果您已经有帐户,请跳过)
- 为 Google Search Console (GSC) API 创建 OAuth 2.0 客户端 ID(如果您已经拥有启用 Search Console API 的 OAuth 客户端 ID,请跳过)
- 将 OAuth 2.0 凭据添加到 Config.py 文件
第一部分:从 Github 下载文件并在 Google Drive 中设置
下载源文件(无需代码)
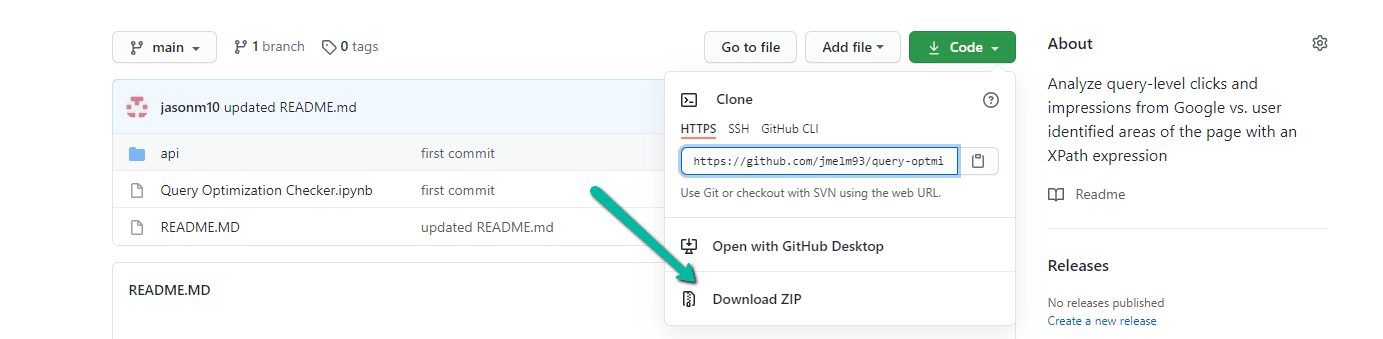
1. 导航到这里。
2. 选择“代码”>“下载 Zip”
*如果您更习惯使用命令提示符,也可以使用“git clone https://github.com/jmelm93/query-optmization-checker.git”。
在 Google Drive 中启动 Google Colab
如果您的 Google Drive 中已经有 Google Colaboratory 设置,请随时跳过此步骤。
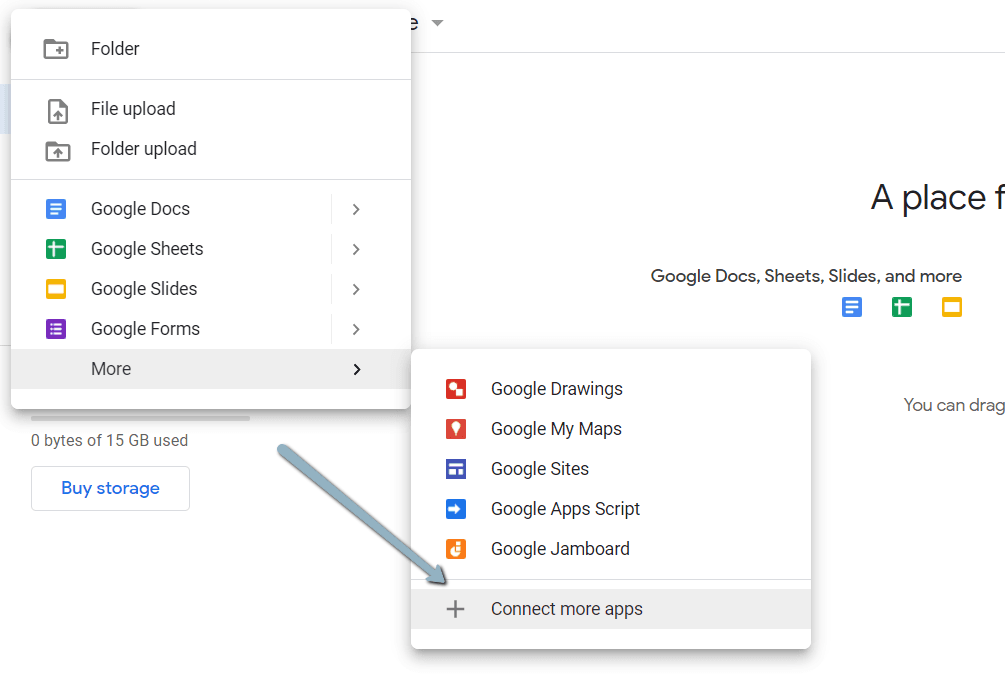
1. 导航到这里。
2. 点击“新建”>“更多”>“连接更多应用”。
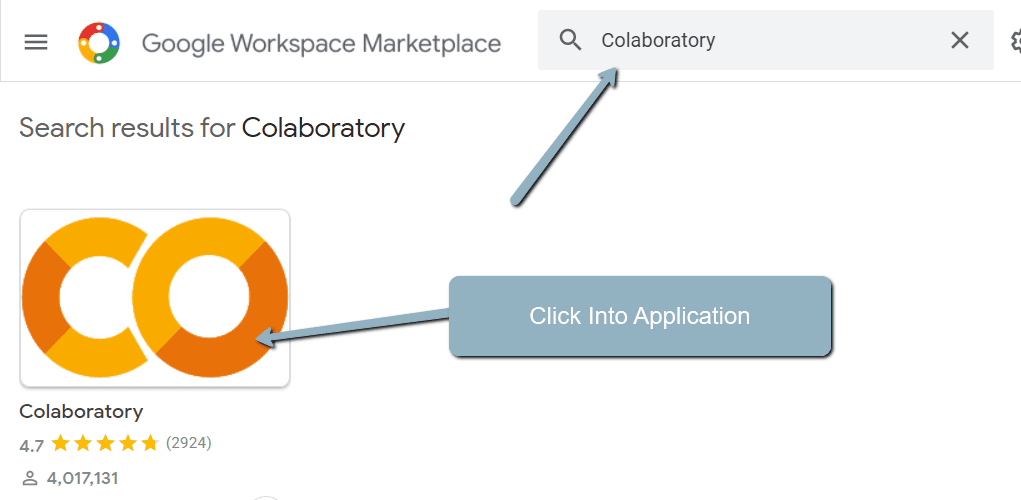
3. 搜索“合作实验室” > 点击进入申请页面。
4. 单击“安装”>“继续”> 使用 OAuth 登录。

5. 单击“确定”并检查提示,以便 Google Drive 自动设置适当的文件以使用 Google Colab 打开(可选)。

将下载的文件夹导入 Google Drive 并在 Colab 中打开
1. 导航到 Google Drive 并创建一个名为“Colab Notebooks”的文件夹。
重要提示:该文件夹需要称为“Colab Notebooks”,因为脚本配置为从“Colab Notebooks”中查找“api”文件夹。
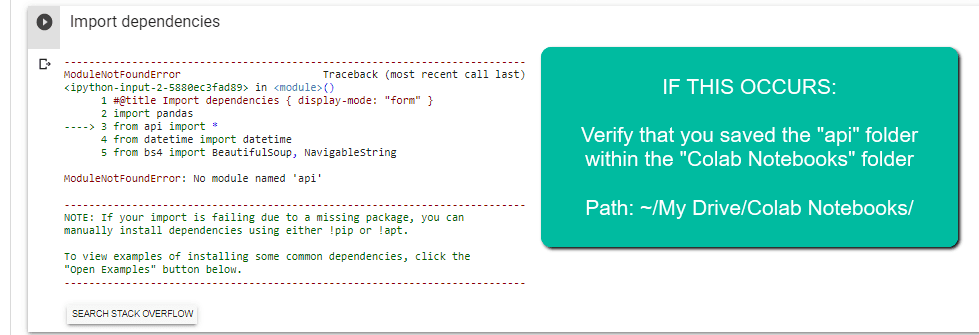 错误导致不正确的文件夹命名。
错误导致不正确的文件夹命名。
2. 将从 Github 下载的文件夹导入 Google Drive。
在此步骤结束时,您的 Google Drive 中应该有一个文件夹,其中包含以下项目:
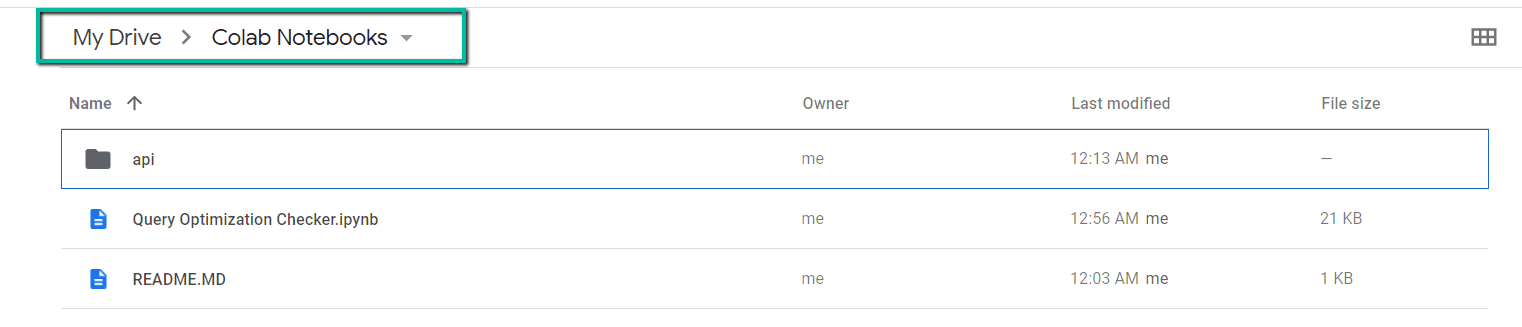
第二部分:设置 Google Cloud Platform (GCP) 项目
如果您已经拥有 Google Cloud Platform (GCP) 帐户,请随意跳过此部分。
1. 导航到 Google Cloud 页面。
2. 点击“免费开始”CTA(CTA 文本可能会随着时间而改变)。
3. 使用您选择的 OAuth 凭据登录。任何 Gmail 电子邮件都可以使用。
4. 按照提示注册您的 GCP 帐户。
系统会要求您提供信用卡进行注册,但目前有 300 美元的免费试用期,Google 指出,在您升级帐户之前,他们不会向您收费。
第三部分:为 Google Search Console (GSC) API 创建一个 0Auth 2.0 客户端 ID
1. 导航到这里。
2. 登录所需的 Google Cloud 帐户后,单击“启用”。
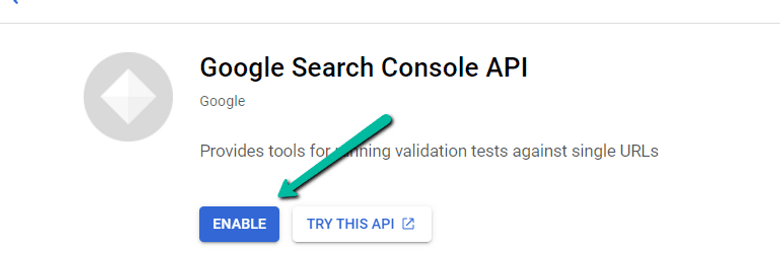
3. 配置同意屏幕。
- 在同意屏幕创建过程中,选择“外部”,然后继续进入“应用程序信息”。
最低要求示例如下:
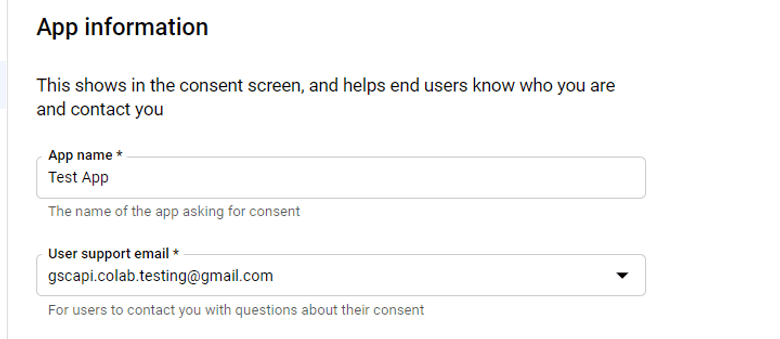
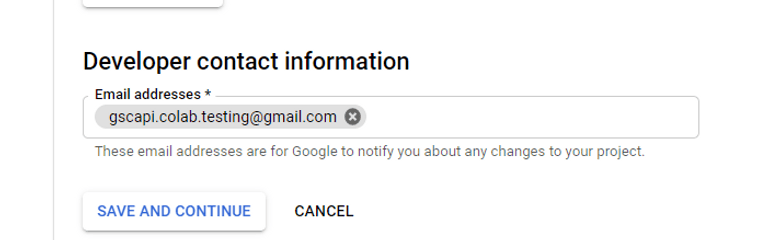
- 跳过“范围”
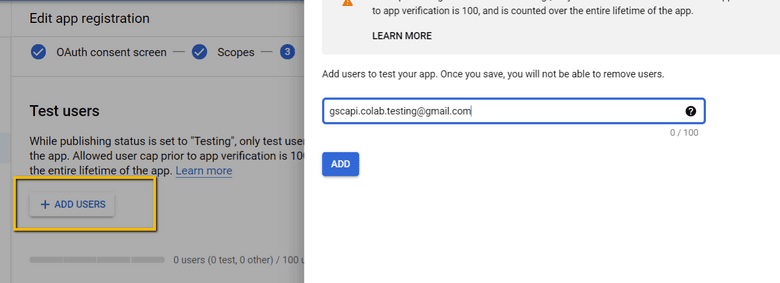
- 将您将用于 Search Console API 身份验证的电子邮件添加到“测试用户”中。可能还有其他电子邮件,而不仅仅是拥有 Google Drive 的电子邮件。一个示例可能是客户的电子邮件,您可以在其中访问 Google Search Console UI 以查看他们的 KPI。
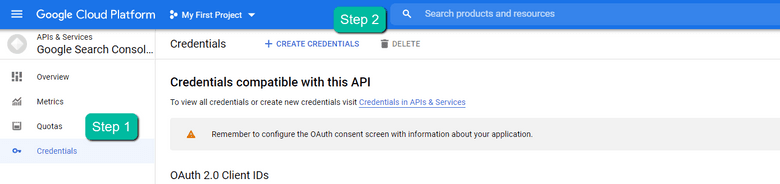
4. 在左栏导航中,单击“Credentials”>“CREATE CREDENTIALS”>“OAuth Client ID”(不在图像中)。
5. 在“创建 OAuth 客户端 ID”表单中,填写:
- 应用程序类型 = 桌面应用程序
- 名称 = Google Colab
- 点击“创建”
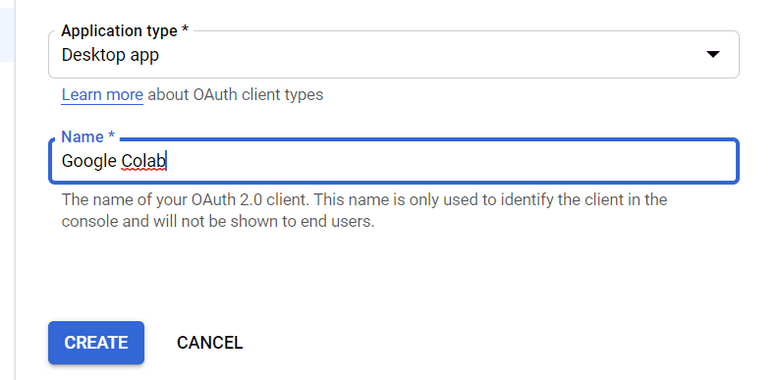
6. 保存“Client ID”和“Client Secret”——因为它们将从我们下载的 Github 文件中添加到“api”文件夹的 config.py 文件中。
- 这些应该在点击“创建”后出现在弹出窗口中
- “客户端密码”在功能上是您的 Google Cloud 的密码(请勿将其发布给公众/在线共享)
第 4 部分:将 OAuth 2.0 凭据添加到 Config.py 文件
1. 返回 Google Drive 并导航到“api”文件夹。
2. 点击进入config.py。
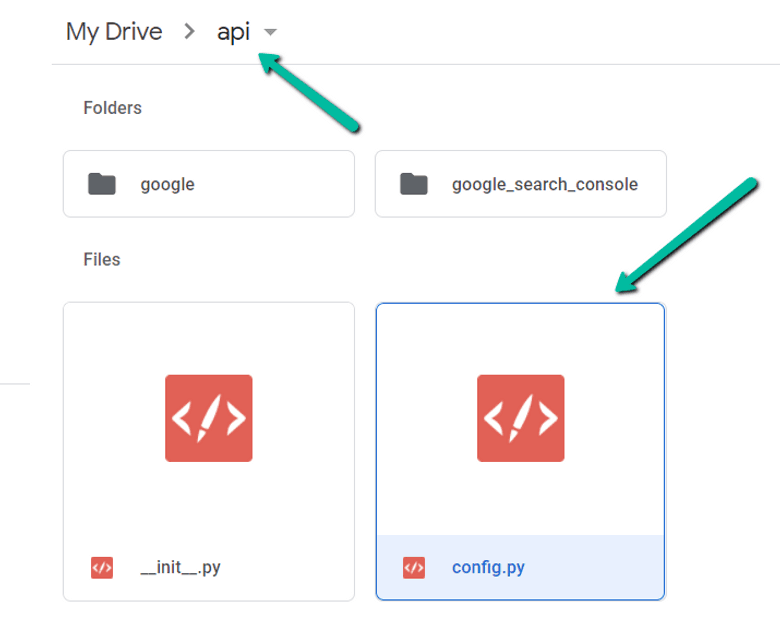
3. 选择使用“文本编辑器”(或您选择的其他应用程序)打开以修改 config.py 文件。
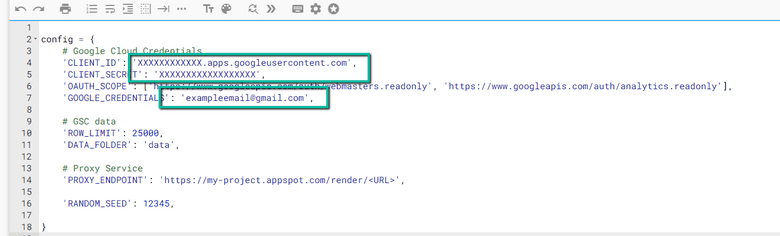
4. 更新下面突出显示的三个区域:
- CLIENT_ID:来自 OAuth 2.0 客户端 ID 设置过程
- CLIENT_SECRET:来自 OAuth 2.0 客户端 ID 设置过程
- GOOGLE_CREDENTIALS:与您的 CLIENT_ID 和 CLIENT_SECRET 对应的电子邮件
5. 文件更新后保存!
恭喜,无聊的事情结束了。您现在可以开始使用 Google Colab 文件了!
运行您的第一个分析
运行你的第一个分析可能有点吓人,但坚持下去,它会很快变得容易。
下面,我们提供了有关所需输入变量的详细信息,以及在运行脚本和分析结果数据集时要牢记的注意事项。
在我们完成这些项目之后,还有一些示例项目和视频演练展示了将这些数据集用于客户可交付成果的方法。
设置输入变量
使用“xpath_selector”变量进行 XPath 提取
您是否曾经想知道每个查询会为您的 <title> 或 <h1> 标记中的网页带来点击次数和展示次数?好吧,这个参数将允许您这样做。
虽然是可选的,但强烈建议使用它,我们认为它“增强”了分析。只需使用 Xpaths 定义站点部分,其余的将由脚本完成。
在上面的视频中,您将找到有关如何创建特定于站点的提取的示例。此外,以下是一些通用提取,几乎可以在网络上的任何网站上使用:
- ‘//title’ # 标识一个<title>标签
- ‘//h1’ # 标识一个<h1>标签
- ‘//h2’ # 标识一个<h2>标签
站点特定:如何仅抓取主要内容(MC)?
链接 Xpaths – 添加“|” Xpath 之间
- ‘//标题 | //h1′ # 在 1 次运行中获取 <title> 和 <h1> 标签
- ‘//h1 | //h2 | //h3′ # 在 1 次运行中获取 <h1>、<h2> 和 <h3> 标签
其他变量
以下是其他变量的视频概述,并对每个变量进行了简短描述。
‘colab_path’ [必需] – Colab 文件所在的路径。这应该是“/content/drive/My Drive/Colab Notebooks/”。
‘domain_lookup’ [必需] – 用于分析的网站主页。
‘startdate’ & ‘enddate’ [必需] – 分析期间的日期范围。
‘gsc_sorting_field’ [必需] – 该工具根据用户定义拉出前 N 个页面。“top”由“clicks_sum”或“impressions_sum”定义。请查看视频以获取更详细的说明。
‘gsc_limit_pages_number’ [必需] – 表示您希望在数据集中获得的结果页数的数值。
‘brand_exclusions’ [可选] – 通常导致品牌查询的字符串序列(例如,任何包含“inseev”的内容都将成为“Inseev Interactive”的品牌查询)。
‘impressions_exclusion’ [可选] – 用于排除由于缺乏预先存在的印象而可能不相关的查询的数值。这主要与在大量页面上具有强大预先存在排名的域相关。
‘page_inclusions’ [可选] – 在所需分析页面类型中找到的字符串序列。如果您想分析整个域,请将此部分留空。
运行脚本
请记住,一旦脚本完成运行,您通常会使用“step3_query-optimizer_domain-YYYY-MM-DD.csv”文件进行分析,但也有其他原始数据集可供浏览。
“step3_query-optimizer_domain-YYYY-MM-DD.csv”文件的实际用例可以在“实际用例和模板”部分找到。
也就是说,在测试时有一些重要的事情需要注意:
1. 无 JavaScript 抓取:如文章开头所述,此脚本不是为 JavaScript 抓取而设置的,因此如果您的目标网站使用带有客户端渲染的 JS 前端来填充主要内容 (MC),则抓取不会有用的。但是,快速获取前 XX(用户定义)查询和页面的基本功能本身仍然很有用。
2. Google Drive / GSC API Auth:第一次在每个新会话中运行脚本时,它会提示您对 Google Drive 和 Google Search Console 凭据进行身份验证。
- Google Drive 身份验证:使用脚本对与 Google Drive 关联的任何电子邮件进行身份验证。
- GSC 身份验证:对有权使用所需 Google Search Console 帐户的任何电子邮件进行身份验证。
- 如果您尝试进行身份验证并收到如下所示的错误,请重新访问第 3 部分第 3 步中的“将您将使用 Colab 应用程序的电子邮件添加到“测试用户”中”上述过程:设置同意屏幕。
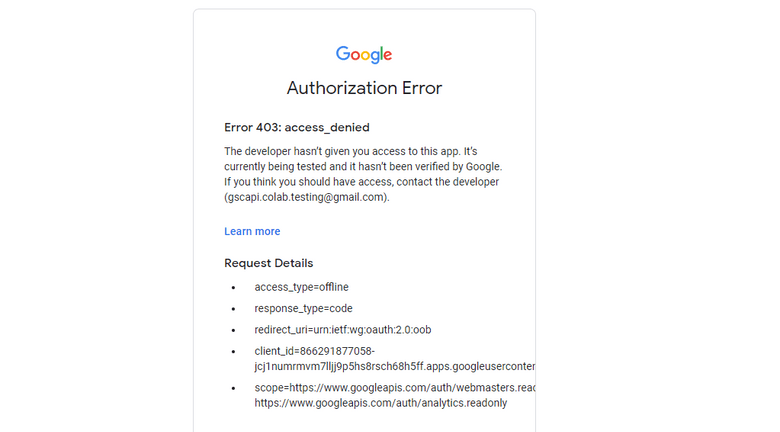
快速提示:Google Drive 帐户和 GSC 身份验证不必是同一个电子邮件,但它们确实需要使用 OAuth 进行单独的身份验证。
3. 运行脚本:导航到“运行时”>“重新启动并运行所有”或使用键盘快捷键 CTRL + fn9 开始运行脚本。
4. 填充的数据集/文件夹结构:脚本填充了三个 CSV——全部嵌套在基于“domain_lookup”输入变量的文件夹结构中。
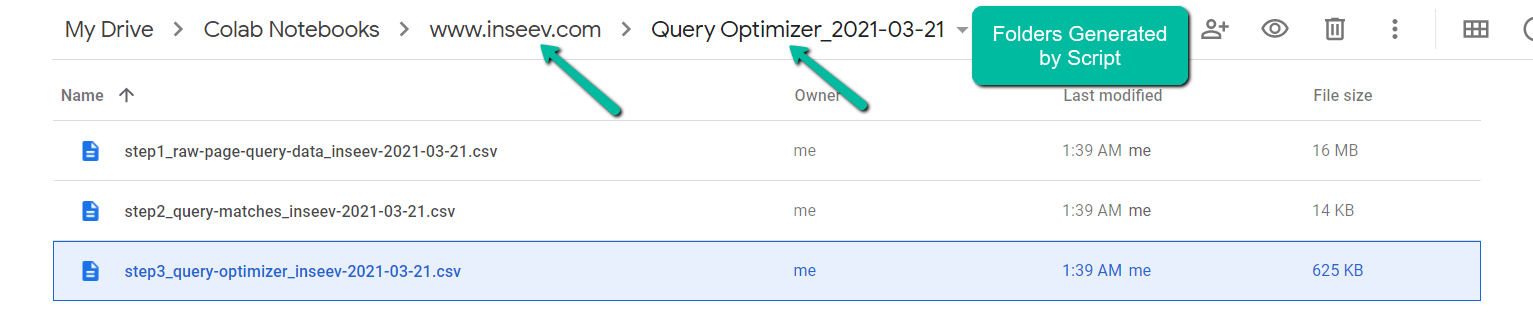
- 自动组织 [文件夹]:每次在新域上重新运行脚本时,它都会创建一个新的文件夹结构,以保持事物的组织性。
- 自动组织 [文件命名]:CSV 包含附加到末尾的导出日期,因此您将始终知道流程何时运行以及数据集的日期范围。
5. 数据集的日期范围:在数据集内部生成一个“gsc_datasetID”列,其中包括提取的日期范围。

6. 不熟悉的指标:生成的数据集包含我们知道和喜爱的所有 KPI——例如点击次数、展示次数、平均(平均)位置——但也有一些您无法直接从 GSC UI 获得:
- ‘count_instances_gsc’ — 查询在指定日期范围内获得至少 1 次展示的实例数。场景示例:GSC 告诉您,对于“送花”等大型关键字,您的平均排名为 6,而您在 30 天的日期范围内仅获得了 20 次展示。你似乎不可能真的在第 6 位,对吧?好吧,现在您可以看到这可能是因为您实际上只出现在该 30 天日期范围内的一天(例如 count_instances_gsc = 1)
- ‘max_position’ & ‘min_position’ — 在指定日期范围内,已识别页面在 Google 搜索中显示的最大和最小排名位置。
快速提示 #1:最大/最小值的较大差异可能会告诉您您的关键字一直在剧烈波动。
快速提示 #2:这些 KPI 与“count_instances_gsc”相结合,可以成倍地加深您对查询性能和机会的理解。
实际用例和模板
访问推荐的多用途模板。
推荐用途:下载文件并与 Excel 一起使用。主观地说,我相信 Excel 与 Google 表格相比,具有更加用户友好的数据透视表功能——这对于使用此模板至关重要。
替代用途:如果您没有 Microsoft Excel 或者您更喜欢其他工具,则可以使用大多数包含数据透视功能的电子表格应用程序。
对于那些选择替代电子表格软件/应用程序的人:
- 以下是设置时要模拟的枢轴字段。
- 您可能需要调整“Step 3 _ Analysis Final Doc”选项卡上的 Vlookup 函数,具体取决于您更新的枢轴列是否与我提供的当前枢轴对齐。
项目示例:标题和 H1 重新优化(视频演练)
项目描述:通过查看 GSC 查询 KPI 与当前页面元素,找到将点击和印象推向高价值页面且不存在于 <title> 和 <h1> 标记中的关键字。使用结果重新优化现有页面的 <title> 和 <h1> 标记。
项目假设:此过程假设将关键字插入 <title> 和 <h1> 标签是谷歌搜索引擎优化相关性优化的强大实践,并且将相关关键字变体包含到这些区域很重要(例如,非完全匹配关键字与匹配 SERP 意图)。
项目示例:页面文本刷新/重新优化
项目描述:找到推动点击和印象的关键字,这些内容不存在于主要内容 (MC) 正文的第一段中。对编辑页面中的介绍性内容进行页面刷新,以包含高价值的关键字机会。
项目假设:这个过程假设在一段内容的前几个句子中插入关键字是一种强大的谷歌搜索引擎优化实践,用于相关性优化,并且将相关的关键字变体包含到这些区域很重要(例如,非完全匹配关键字与匹配SERP 意图)。
最后的想法
我们希望这篇文章对您有所帮助,并让您了解使用 Python 和 Google Colab 来增强您的相关性优化策略的想法。
正如整篇文章所述,请记住以下几点:
- Github 存储库将根据我们将来所做的任何更改进行更新。
- 存在未发现错误的可能性。如果发生这些情况,Inseev 很乐意提供帮助!事实上,我们非常感谢您伸出援手调查并修复错误(如果确实出现)。这样其他人就不会遇到同样的问题。
除了上述之外,如果您对 Colab(双关语)数据分析项目的方式有任何想法,请随时提出想法。



